- 기본적으로 데이터를 다룰 때는 pandas, numpy 모듈을 늘 달고 사는 것 같다.
- 시각화에는 Matplotlib 모듈을 자주 쓴다. 물론 .plot으로 자체적으로 가능하지만, 더 많은 기능이 있는 듯하다.
데이터 다듬기
- 시각화에서 중요한 것은 "데이터 정렬"
CCTV_Seoul.sort_values(by="소계", ascending = False).head()
# by="정렬기준"
# ascending은 오름차순이다. False를 하면 내림차순.
# head()는 기본 상위 5개를 보여주고, 괄호 안에 숫자를 넣으면 그 수만큼 보여준다.
- 최근 증가율(2014, 2015, 2016이 2013년도 이전에 비해 얼마나 증가했는지)이 중요한 지표가 될 수 있을 것 같아서, 컬럼을 추가하려고 한다.
CCTV_Seoul["최근증가율"] = (
(CCTV_Seoul["2016년"] + CCTV_Seoul["2015년"] + CCTV_Seoul["2014년"]) / CCTV_Seoul["2013년도 이전"] * 100
)
CCTV_Seoul.sort_values(by="최근증가율", ascending=False).head()
# 컬럼 지정해서 값을 추가하면, 그냥 컬럼 자체가 추가된다.
# 만약 이미 존재하는 컬럼명이라면, 그 컬럼의 값이 추가한 값으로 업데이트 된다.
# 최근증가율을 기준으로 내림차순 정렬했고, 상위 5개를 보여준다.
- 필요 없는 행 발견
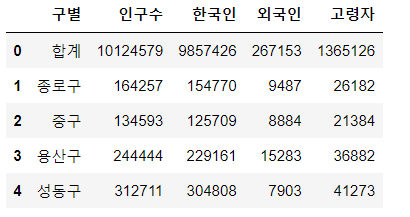
- 행 삭제는 drop()을 활용한다.
pop_seoul.drop([0], inplace=True)
pop_seoul.head()
# .drop([삭제할 행의 인덱스 번호])
# drop 적용 후에 그대로 해당 내용을 저장하려면 inplace=True를 꼭 붙여줘야 함
# drop 적용 후 pop_seoul의 상위 5개를 보여준다.(합계 행이 사라졌다)
- unique() 함수는 해당 컬럼의 어떤 값들이 있는지를 중복 없이 알 수 있도록 해준다.
- unique() 를 했는데 NaN 값 등이 있으면, 데이터를 정리할 수 있는 기회를 준다.
pop_seoul["구별"].unique()
# '구별' 컬럼의 unique 함수를 지정하는 코딩
- unique()를 통해서 얻은 값들이 총 몇 개 있을지도 궁금하다. len()을 활용한다. -> '25'라고 출력된다.
len(pop_seoul["구별"].unique())- 필요없는 컬럼을 제거할 때는 del이나 drop을 사용하면 된다. del을 활용해봤다.
del data_result["2013년도 이전"]
data_result.head()
# del df["컬럼명"] 이라고 입력하면, 해당 컬럼이 삭제된다.
# 삭제된 후에는 데이터가 바로 사라지니 주의해야 한다.
# 한번 더 삭제를 누르면, 이미 해당 컬럼이 없기 때문에 에러가 뜬다.
cf) drop을 활용하려면 아래와 같이 하면 된다.
df.drop("C", axis=1) # 행은 axis=0, 열은 axis=1 적용

- index 열을 '구별'로 진행하고 싶다.

- 이럴 때는, set_index()를 활용해서 '구별' 컬럼으로 인덱스를 바꿀 수 있다.
data_result.set_index("구별", inplace = True)
data_result.head()
# df.set_index("인덱스로 지정할 컬럼명") 의 형태로 쓴다.
# 저장이 안 되는 것이 디폴트라서, inplace를 꼭 써줘야 한다.
- 컬럼의 데이터들이 어떤 상관관계를 가지는지 궁금하다.
C.f. 상관관계의 계수
- x와 y가 상관관계가 있다고 하면, x가 변할 때 y가 변하는 것을 의미한다.
- 얼마나 변하냐와 관련한 것이 상관관계의 계수이다.
- 보통 계수가 0.2 이하이면 상관관계가 없거나 무시해도 좋은 수준
- 0.4 이하는 약한 상관관계
- 0.4 이상은 강한 상관관계- 상관관계를 볼 때는 corr()을 활용한다.
data_result.corr()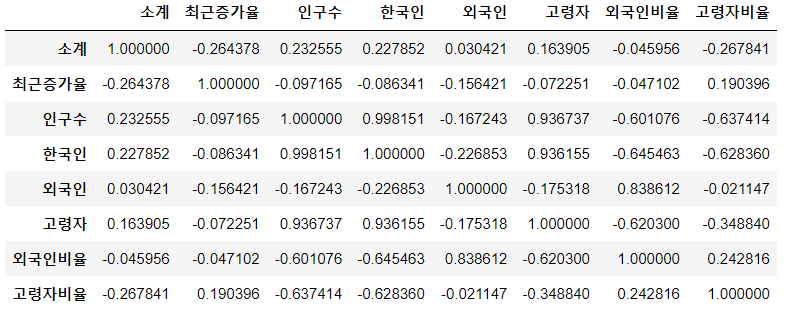
- 그래서, 인구수와 관련한 비율 컬럼을 추가한다.
data_result["CCTV비율"] = data_result["소계"] / data_result["인구수"] * 100
data_result.sort_values(by="CCTV비율", ascending=False).head()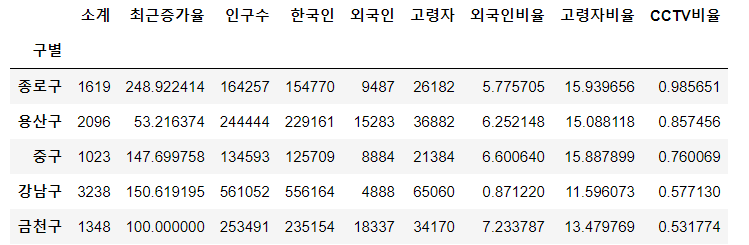
matplotlib 기초
- jupyter notebook 에서 시각화를 하기 위해서는 초기에 설정할 몇 가지 있다.
- 살짝 복잡해서 외우는 데에 시간이 좀 걸렸다.
import matplotlib.pyplot as plt # pyplot 만 가져와서 plt로 부를게
from matplotlib import rc
rc("font", family="Malgun Gothic") # 한글 지원하기
%matplotlib inline # 그림 그릴거야
plt.rcParams["axes.unicode_minus"] = False # 그림 그릴 때 마이너스 값들 에러나지 않게 하자- 나중에는 다 저장해놓고 불러와서 쓸 예정!
- 가장 기본이 되는 건 figure(), plot(), show()
plt.figure(figsize=(10,6))
plt.plot(x, y)
plt.show()
# figsize= 을 통째로 외우자.. 자꾸 =을 빼먹는다.
# plot 에는 x와 y를 지정해줘야 한다.
# show()를 불러야지 그린다.- 넘파이 모듈을 이용해서, x값에 해당하는 t를 점으로 찍고, y는 sin함수로 표현한다.
t = np.arange(0, 12, 0.01) # 0부터 12까지 0.01 간격으로 점 생성
y = np.sin(t) # numpy 모듈의 sin 함수를 활용- 보통 그래프를 그리는 것은 drawGraph() 등의 함수로 정의해서 통째로 호출한다.
def drawGraph():
plt.figure(figsize=(10,6))
plt.plot(t, y, label='sin') # 위에 만들어 놓은 t, y를 그릴거고, 그래프 이름표는 sin으로
plt.plot(t, np.cos(t), label='cos') # 그래프 비교해보려고, y 대신 cos그래프, 이름표는 cos으로
plt.grid() # 그리드 추가
plt.xlabel("time") # x축 이름을 time으로
plt.ylabel("Amplitude") # y축 이름을 Amplitude로
plt.title("Example of sinewave") # 그래프 이름을 이걸로
plt.show() # 그려주세요.
drawGraph()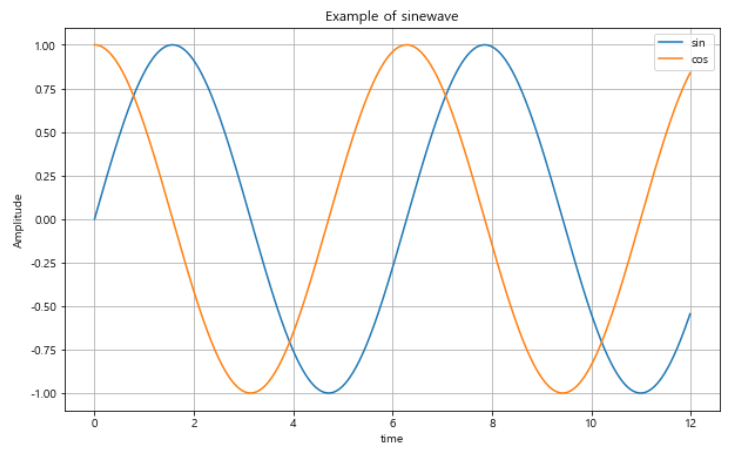
- x축 점을 0부터 5까지 0.5 간격으로 찍어서 1, 2, 3차 함수 그래프를 그려봤다.
t = np.arange(0, 5, 0.5)
def drawGraph():
plt.figure(figsize=(10, 6))
plt.plot(t, t)
plt.plot(t, t**2)
plt.plot(t, t**3)
plt.show()- 실행하기 전에, 간단하게 그래프의 모양을 좀 예쁘게 꾸몄다.
t = np.arange(0, 5, 0.5)
def drawGraph():
plt.figure(figsize=(10, 6))
plt.plot(t, t, "r--") # 빨간색 점선 --
plt.plot(t, t**2, "bs") # 파란색 사각형
plt.plot(t, t**3, "g^") # 녹색 삼각형
plt.show()
drawGraph()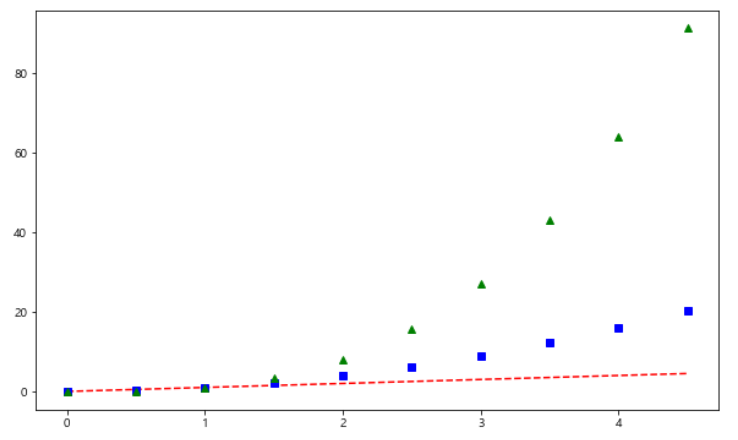
- 그래프 서식에 대해서 더욱 자세히 살펴본다.
- 옵션에는 color, linestyle, marker, markerfacecolor, markersize를 지정할 수 있다.
- 각 x, y축의 한계선도 지정할 수 있다.
x=[0,1,2,3,4,5,6]
y=[1,4,5,8,9,5,3]
def drawGraph():
plt.figure(figsize=(10,6))
plt.plot(
x,
y,
color="green",
linestyle="dashed",
marker="o",
markerfacecolor="blue",
markersize=12
)
plt.xlim([-0.5, 6.5])
plt.ylim([0.5, 9.5)
plt.show()
drawGraph()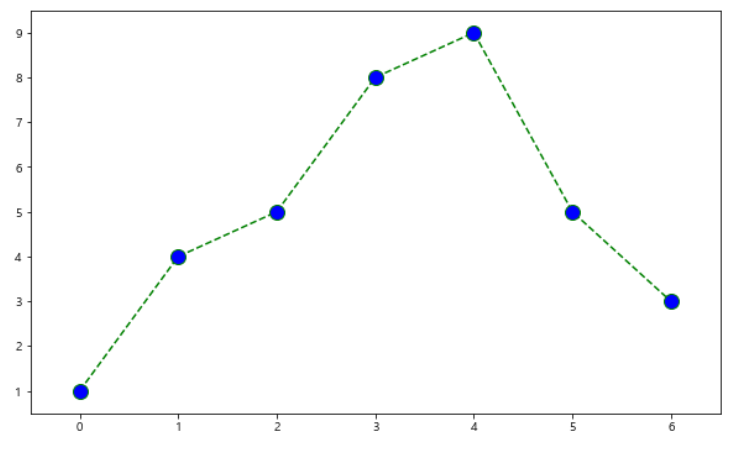
- 컬러맵, 컬러바를 포함한 산점도를 그렸다. scatter(), c=colormap, colorbar() 기억하기!
colormap = x
def drawGraph():
plt.figure(figsize=(10,6))
plt.scatter(x, y, c=colormap, marker=">") # 컬러맵의 컬러를 찍을 기준은 x이다. 마커는 오른쪽이 뾰족한 삼각형
plt.colorbar() # 우측 컬러바 추가
plt.show()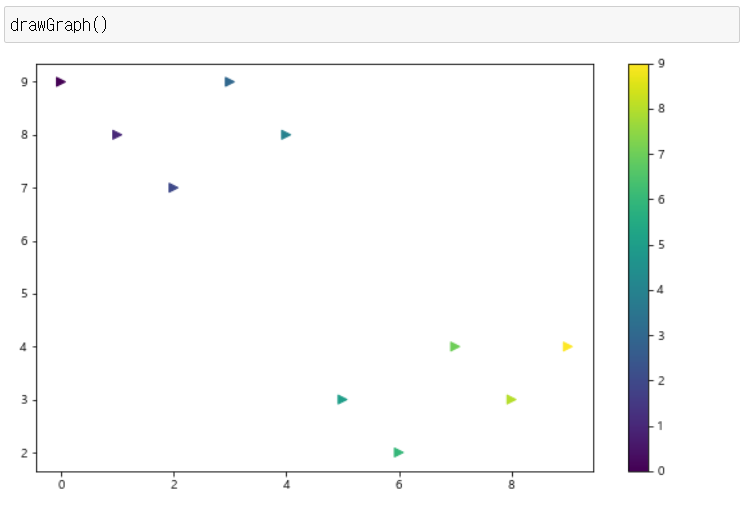
Pandas에서 기본적으로 제공하는 plot
from matplotlib import rc
plt.rcParams["axes.unicode_minus"]=False # 마이너스 값을 그리면 오류가 날 때가 있어서 미리 대처
rc("font", family="Malgun Gothic") # 한글에 대해서 오류가 날 때가 있어서 미리 대처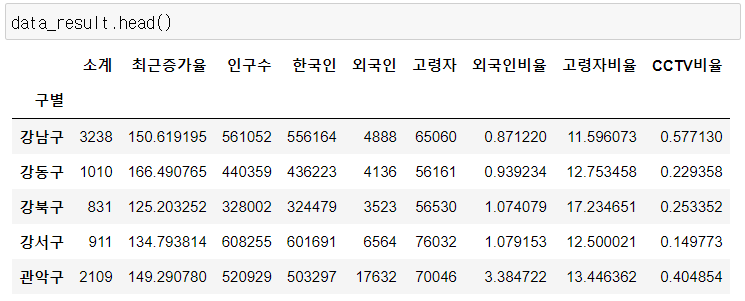
- 지금 우리가 가진 data_result 데이터프레임을 활용해서, 기본 pandas에서 제공하는 plot 기능을 살펴본다.
- 간단하게 .plot()을 붙이면 된다.
data_result.plot()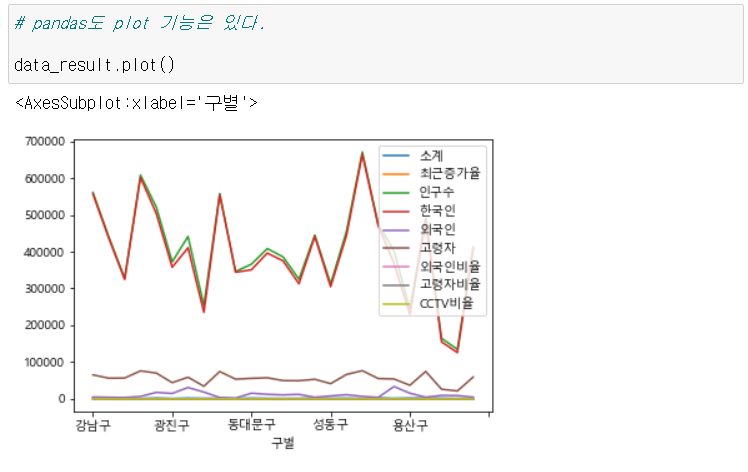
- 전체 컬럼 말고, 소계에 대해서만 그래프를 그리려고 하면, 지정해서 그리면 된다.
data_result["소계"].plot()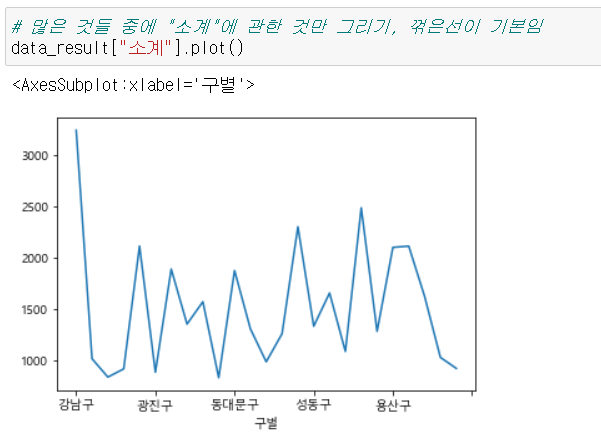
- 꺾은선 말고, 막대 그래프로 그리고 싶다면, kind= 명령을 활용하면 된다.
- 세로 막대는 bar, 가로 막대는 barh
data_result["소계"].plot(kind="bar", grid=True, figsize=(10,10))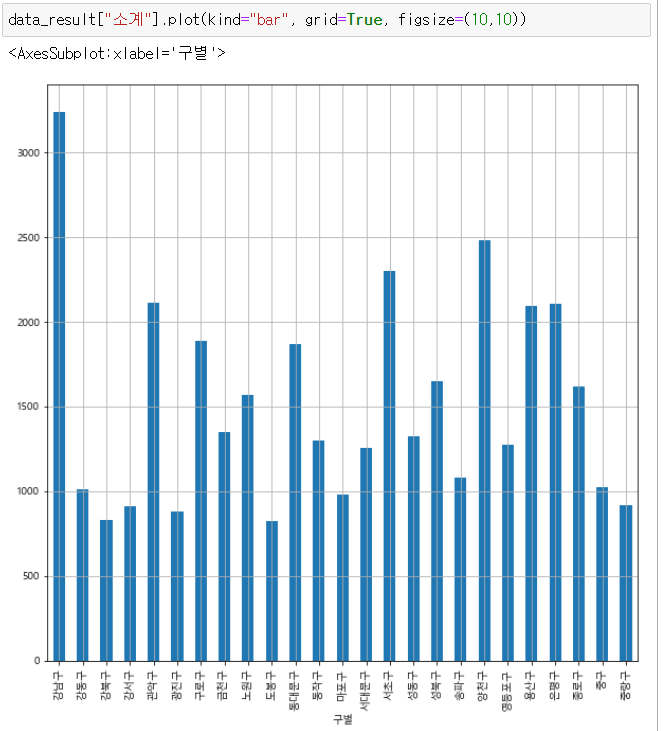
data_result["소계"].plot(kind="barh", grid=True, figsize=(10,10))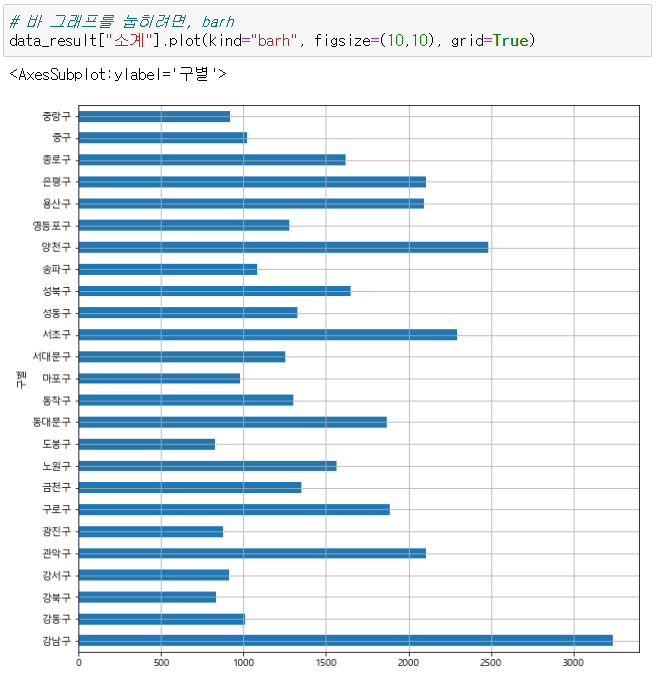
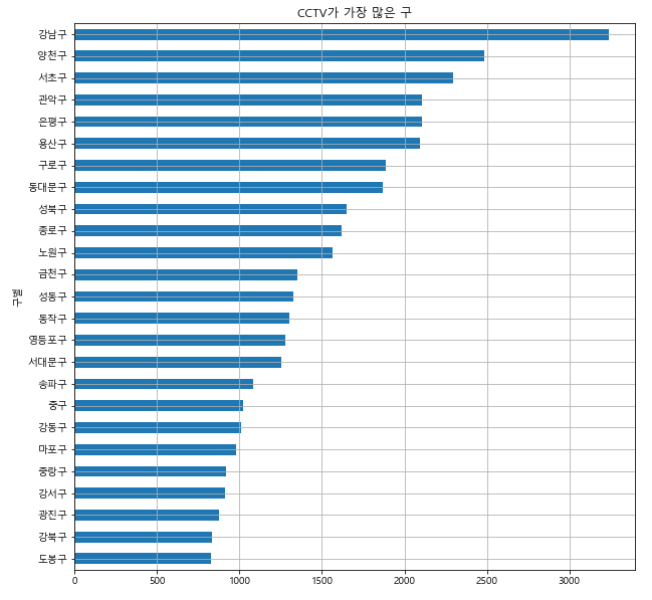
- 정렬(.sort_values())을 응용해서, CCTV가 많은 순으로 가로 막대 그래프를 그리면 다음과 같다.
data_result["소계"].sort_values().plot(
kind="barh",
figsize=(10,10),
grid=True,
title="CCTV가 가장 많은 구"
)
시각화 둘째 날 후기
데이터로 그림을 그리는 일이 생각보다 재밌다.
옵션을 지정하는 일이 만만찮긴 한데, 익숙해져야지 뭐.
시각화를 통해 많은 사람들에게 내 의견을 피력하는 날이 오길 바라면서.
- 네카라쿠배 데이터사이언스 오프라인 1기 수강 中
제로베이스 - 밑바닥부터 끝까지 듣는 온라인 강의
무조건 간다! 개발자 스쿨 '네카라쿠배', 끝까지 공부하는 '온라인 완주반', 전문가가 베스트셀러를 해석해 주는 '한달한권' 등 교육 서비스로 삶의 전환점을 제공하는 제로베이스입니다.
zero-base.co.kr
'Data Science' 카테고리의 다른 글
| [seaborn] 데이터 정리 및 다양한 시각화 실행 (0) | 2021.10.14 |
|---|---|
| [pandas.pivot_table] 피봇테이블, 개꿀. (0) | 2021.10.13 |
| [matplotlib] colormap 형태의 산점도와 선형 회귀식, 그리고 오차 표현 (0) | 2021.10.13 |
| [pandas] DataFrame(데이터프레임) 쪽지시험;Quiz 후기 (0) | 2021.10.07 |
| [Pandas] DataFrame(데이터프레임) 알아보기 (0) | 2021.10.06 |




댓글