반응형
- 문장은 일련의 토큰(tokens)으로 구성되어 있습니다.
- 텍스트 토큰은 주관적, 임의적(arbitrary)인 성격을 띄고 있습니다.
- 토큰을 나누는 기준은 다양합니다.
- 공백(White space)
- 형태소(Morphs)
- 어절
- 비트숫자
- 컴퓨터에게 단어를 숫자로 표현하기 위해서, Vocabulary을 만들고, 중복되지 않는 인덱스(index)로 바꿉니다.
- 궁극적으로 모든 문장을 일련의 정수로 바꿔줍니다. 이를 인코딩(Encoding)이라고 합니다.
- 하지만 관계없는 숫자의 나열로 인코딩하는 것은 우리가 원하는 것이 아닙니다. 여전히 주관적인 숫자들 뿐입니다.
- 우리는 비슷한 의미의 단어는 같이 있고, 아니면 멀리 떨어져 있는 관계를 만들고 싶습니다.
- 그렇다면 어떻게 관계를 만들어 줘야 할까요?
- 한 가지 방법으로 "One hot Encoding"이 있을 수 있습니다.
- 길이가 단어장의 총 길이(∣V∣)인 벡터에서, 단어의 index 위치에 있는 값은 1, 나머지는 0으로 구성합니다.
- 단점: 모든 토큰 간에 거리가 같습니다. 하지만 모든 단어의 뜻이 같지 않기 때문에 거리가 달라져야 저희가 원하는 단어간의 관계가 성립 됩니다.
- 한 가지 방법으로 "One hot Encoding"이 있을 수 있습니다.
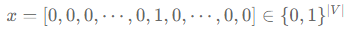
- 어떻게 신경망이 토큰의 의미를 잡아낼수 있을까요?
- 결론은 각 토큰을 연속 벡터 공간(Continuous vector space) 에 투영하는 방법입니다. 이를 임베딩(Embedding) 이라고도 합니다.
- Table Look Up: 각 one hot encoding 된 토큰에게 벡터를 부여하는 과정입니다. 실질적으로 one hot encoding 벡터( x )와 연속 벡터 공간( W )을 내적 한 것 입니다.
- Table Look Up 과정을 거친후 모든 문장 토큰은 연속적이고 높은 차원의 벡터로 변합니다.
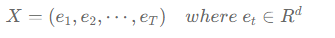
본 내용은 부스트코스 조경현 교수의 딥러닝을 이용한 자연어 처리 수업 내용입니다.
반응형
'Data Science > NLP' 카테고리의 다른 글
| Language Modeling (0) | 2022.03.30 |
|---|---|
| CBoW & RN & CNN & Self Attention & RNN (0) | 2022.03.28 |
| Text classification Overview (0) | 2022.03.28 |
| Gradient-Based Optimization (0) | 2022.03.28 |
| Backpropagation (0) | 2022.03.28 |
댓글