DataFrame : 2차원 형태의 데이터를 다루기 위한 자료형
- 표 형식의 데이터를 담는 자료형
- Columns, Index, Values로 구성되어 있다.
- 행 / 열 = index / column
- index는 각 레코드, column은 각 데이터의 특징를 설명하는 '이름' 같은 존재
(개인적으로.. 2차원 numpy array의 부가적인 기능을 가능하게 하는 것이 Pandas 같은 느낌)

- 처음에 불러오면 index는 0, 1, 2 등으로 번호가 매겨져 있다.
1) CSV 파일 불러오기

- pandas를 import하고, pd라고 별칭을 만들어주는 과정을 꼭 맨 처음에 하자!
- 중요한 포인트는, minho라는 폴더 안에 저 파일이 있다는 걸 인지한 상태에서 코딩하는 것이다.
- 불러올 때도 위에 좀 떼고, 컬럼 선택해서 가져올 수 있다. header=2, usecols="A,B" 이런 식으로 쓰면 위에 2줄 빼고 A, B 컬럼만 가져오겠다는 말이다. 예시는 아래 참고.
- 헤더가 없으면, header = None 넣어줘야 함
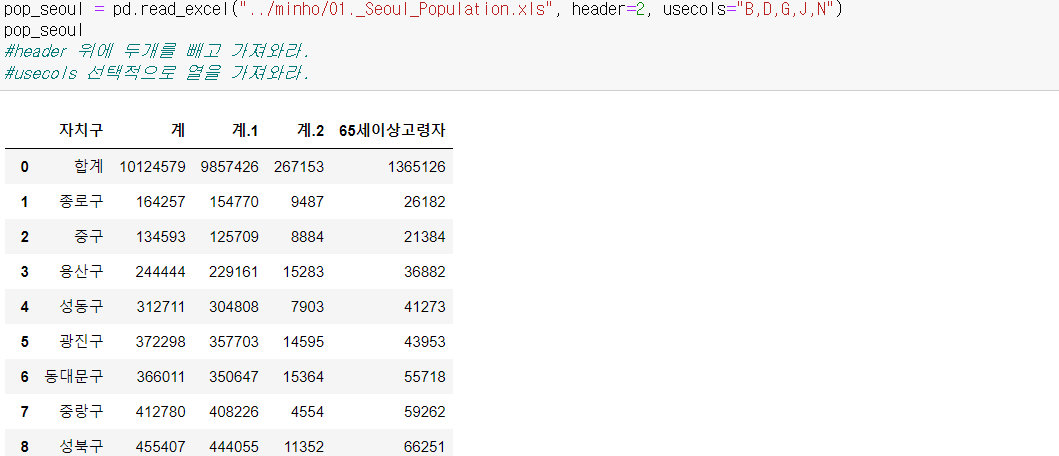
2) DataFrame 뜯어보기 - CCTV_Seoul

※ index, columns, head(), tail()
- columns : index도 입력하면 비슷하게 나오겠지?

- 컬럼 번호를 누르면 그 컬럼 이름이 나온다.

- head() : 처음부터 5개가 기본이고, 괄호 안에 숫자를 넣으면 그 갯수만큼 나온다.

- tail() : 마지막부터 5개가 기본이고, 괄호 안에 숫자를 넣으면 그 갯수만큼 나온다.

※ 인덱스, 컬럼 이름 바꿔주기 Rename
- rename(columns={"기존이름" : "신규이름"})

- 여기서 포인트는 inplace를 안하면 아예 바뀐게 아니라, 바뀐 모습만 잠깐 보여주는 느낌?
- 아래와 같이 inplace=True를 하면 아예 바뀐다.

3) DataFrame 더 뜯기 - pop_seoul

- 여러 개의 컬럼명을 바꾸려면, 어떻게 하는가. 딕셔너리 느낌으로 간다, 쉼표 찍고 냅다 입력.

3) Series(시리즈) : 쉽게 생각하면 '열 정보 하나'를 말한다.
- index와 value로 이루어져 있음
- ★ 한 가지 데이터 타입만 가질 수 있음


- '브로드캐스팅' 이라는 것도.... 오늘 들어봤다. 머신러닝이나 딥러닝 때 또 나온단다.. 와.. (?)

4) 날짜 데이터도 pd로 만들 수 있다.

- pd.date_range
- 시작 날짜 쓰고, 기간(몇 일 할건데?) 쓰면 된다.
- freq는 단위?라고 생각하면 될 것 같다.
5) numpy 난수 생성(random.randn) 활용해서 데이터프레임 만들기

- 이렇게 만든 것을 DataFrame으로 넘긴다.

6) DataFrame 정보 탐색 - 난수 생성해서 만든 "df"를 활용
- head()와 tail()은 앞에서 봤지?

- 데이터프레임 3요소 탐색 : 인덱스index, 컬럼columns, 밸류Values

- df.info() : 데이터프레임의 전체 정보를 알려준다.

7) 데이터 정렬 - sort_values()
- 특정 컬럼(열)을 기준으로 데이터를 정렬
- 기본적으로 오름차순으로 정렬된다.
- 내림차순으로 하고 싶으면, ascending=False
- 이것도 정렬해서 완전히 고치려면, inplace=True
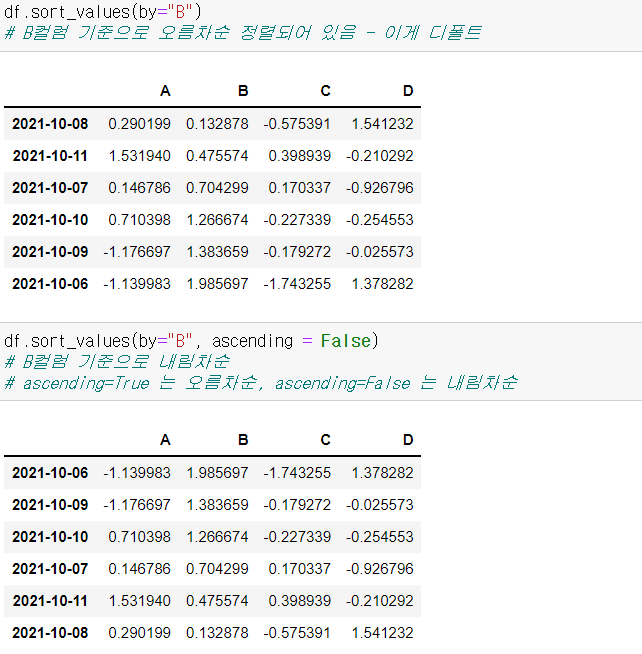
- 정렬 기준을 2개 이상하려면, 리스트 형식으로 넣는다.

8) 조회;인덱싱;오프셋;Offset
※ [n:m] :- n부터 m-1까지
- n, m을 "인덱스나 컬럼의 이름으로 지정"해서 진행하는 경우에는 m-1이 아닌 m으로 진행함(포함)

- [0:3]이라면 2번 인덱스까지 슬라이싱됨.

- loc : location의 약자
- df.loc[행, 열]의 형태로 적는다.
- 모두 가져올 때는 ':'를 적는다.


- iloc : inter location 의 약자
- 컴퓨터가 인식하는 인덱스 값으로 선택할 때, iloc을 사용하는데, 위치로 인덱싱한다는 말이다.

9) 조건;Condition
- 불린(Boolean) 활용
- df["A"] > 0 : A열에서 0보다 큰 애들은 True로, 아닌 애들은 False로 나옴

- 그럼, 그런 애들을 값으로 보여주는 건 어떻게? True 된 애들을 또 다시 넣어줌.

- 데이터프레임 안에 '그 값'이 존재하는지 물어보는 "isin()"

10) 컬럼 추가, 수정, 삭제
- 컬럼 자체에 값을 선언 : 기존 컬럼이 있으면 값이 수정되고, 없으면 신규로 추가됨

- 컬럼 삭제는 del

- 컬럼 삭제의 또다른 방법은 drop
- drop의 경우는 가로를 지울지 세로를 지울지 적어줘야 함
- 열이라면 axis=1, 행이라면 axis=0


11) 데이터프레임에 함수를 적용 : apply
- df.apply(함수이름)의 형태로 적는 듯하다.
(어려워.. 다음에 다시 나오면 익숙해지겠지?)

- np.sum 은 각 열의 밸류를 다 더한 값이 나온 듯하다.
- min 은 각 열의 최소값이 나왔다.
- 열 1개만 지정해서 적용할 수도 있다.

- 함수를 정의해서, 그 함수를 apply로 적용할 수도 있다.

- lambda식 표기도 알아두면 좋을 것 같다.

Cf.
Pandas(판다스라고 읽는다)
- Python에서 R만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
- 단일 프로세스에서는 최대 효율 (Pandas 만으로도 많은 것들이 가능하다는 말)
- 코딩 가능하고 응용 가능한 엑셀로 받아들여도 됨
- 스테로이드 맞은 엑셀
시각화 첫 날 후기
Pandas를 오랜만에 쪼갰더니, 쉽지 않았다..
DataFrame 이거 왜 필요한지도 아직은 딱히 안 느껴지지만,
함께 공부하는 친구가 꼭 필요하고, 강력한 툴이래서 열심히 공부했다..
친구야 멋있다.. 너라도 잘해서 다행이다.. 얼른 따라갈게..ㅎ
(비전공자는 웁니다. 엉엉)
- 네카라쿠배 데이터사이언스 오프라인 1기 수강 中
제로베이스 - 밑바닥부터 끝까지 듣는 온라인 강의
무조건 간다! 개발자 스쿨 '네카라쿠배', 끝까지 공부하는 '온라인 완주반', 전문가가 베스트셀러를 해석해 주는 '한달한권' 등 교육 서비스로 삶의 전환점을 제공하는 제로베이스입니다.
zero-base.co.kr
'Data Science' 카테고리의 다른 글
| [seaborn] 데이터 정리 및 다양한 시각화 실행 (0) | 2021.10.14 |
|---|---|
| [pandas.pivot_table] 피봇테이블, 개꿀. (0) | 2021.10.13 |
| [matplotlib] colormap 형태의 산점도와 선형 회귀식, 그리고 오차 표현 (0) | 2021.10.13 |
| [matplotlib] 데이터 다듬어서 간단한 시각화 다뤄보기 (0) | 2021.10.13 |
| [pandas] DataFrame(데이터프레임) 쪽지시험;Quiz 후기 (0) | 2021.10.07 |




댓글