1. What are Anomalies?
1) Anomaly v.s. Novelty
- Anomaly : 정상 데이터와 본질적으로 다름
- Novelty : 정상 데이터와 본질적으로 같지만 유형이 다름
- ex) 호랑이가 정상데이터일 때, 백호는 Novelty, 그 밖에 말, 치타 등은 Anormaly (Figure 4)
2) Type of Anomalies

- Point : 말 그대로 이상치 -> 정상과 본질적으로 다른 희소한 데이터(발생 빈도가 매우 낮음)
- Contextual of Conditional : 조건부 이상치 -> 특정 조건이 충족될 때 이상치로 판단될 수 있음
- Collective or Group : 한 번 이상치가 발생할 때, 대규모로 발생하는 경우 ex. 디도스 공격

3) Label of Anomalies
※ Anomaly Detection 학습에 있어서 가장 중요한 요소는 Label 활용 가능 여부
- 각 경우에 따른 차이점을 이해하고 올바른 모델을 사용하는 것이 중요함
- 일반적으로는 반지도학습으로 진행함
(1) 지도 학습 : 정상 데이터와 비정상 데이터에 대한 라벨이 모두 존재
A. 장점
- 라벨 정보로 인한 높은 Detection 성능
- 사실상 Classification 문제와 동일하기 때문에 Classification 모델을 사용할 수 있어 모델 선택의 폭이 넓음
B. 단점
- 라벨 정보가 존재한다는 것은 현실적으로 불가능한 경우가 매우 많음
- 라벨 정보가 존재하더라도 정상/비정상 데이터 셋 간 Class 불균형으로 인한 문제 발생 가능성이 있음
(2) 반지도 학습 : 정상 데이터에 대한 라벨만 존재하는 경우, 즉 무엇이 비정상인지 알 수 없음
A. 장점
- 대부분의 경우 정상 데이터와 그에 따른 라벨을 확보하는 것은 가능함, 즉 가장 현실적인 경우를 가정하고 있음
- 비지도 학습에 비해 모델의 성능이 보장됨
B. 단점
- 정상 데이터만으로 학습하기 때문에 학습된 Representation Feature가 과적합될 확률이 높음
- 일반적으로 지도 학습과 비교하여 모델 성능이 떨어짐
(3) 비지도 학습 : 전체 데이터가 주어져 있고, 라벨 정보가 전혀 없는 경우
A. 장점
- 어떠한 경우라도 사용할 수 있는 방법론
B. 단점
- 전체 데이터셋의 대부분이 정상 데이터라는 가정이 필요함
- 앞선 두 경우와 비교하여 일반적으로 가장 성능이 떨어지고, noise에 민감함
2. Anomaly Detection Model (Miscellaneous Techniques)
1) 3 Types : 머신러닝, 딥러닝, Hybrid 모델, 총 3가지 유형

- 기본적으로는 반지도 학습을 가정한 방법론들
- 비지도 학습에 가능하지만, 이는 해당 데이터셋에 비정상 데이터가 매우 적은 양 존재할 것이라는 가정에서 근거함
(1) ML Model
A. 특징
- 비정형 데이터에 대해 작동할 수 없음
- SVM/Tree 등 이미 많은 Anomaly Detection 방법론이 개발되었고, 정형데이터에 대해 준수한 성능이 보장됨
B. 예시
- OC-SVM, SVDD
- Isolation Forest
- Clustering
(2) DL Model
A. 특징
- 비정형 데이터 혹은 시계열 데이터에 대해서도 Anomaly Detection이 수행 가능함 (Input 상관 없이 가능)
- 모델 구조 및 학습을 위한 loss 함수를 어떻게 설계하는지가 관건이라고 할 수 있음
B. 예시
- AutoEncoder(AE) 계열
- Word2Vec 계열
- GAN 계열
- Deep SVDD(One Class Neural Networks)
(3) Hybrid Model
A. 특징
- 딥러닝 모델을 Feature Extractor로 활용하여 비정형 데이터에 대해서도 머신러닝 모델을 적용할 수 있게 함
- End-to-end 학습이 불가능하기 때문에, 엉뚱한 feature로 인해서 성능 저하 우려
B. 예시
- AE 계열 + 머신러닝
- Word2Vec 계열 + 머신러닝
2) Model Detail
(1) SVM(Support Vector Machine)
- 가장 대표적인 모델로, OC-SVM(=1-SVM)와 SVDD가 존재함
A. OC-SVM(One-Class-SVM=1-SVM)
- 정상 데이터를 원점으로부터 멀리 위치하도록 하고, 정상과 비정상을 구분하는 최적의 초 평면을 계산하여 Anomaly Detection
- 원점과 가까울 수록 비정상이고, 원점에서 멀리 떨어져 있을수록 정상 데이터라고 판단함
B. SVDD(Support Vector Data Description)
- 데이터를 감싸는 가장 작은 구 형태의 초 평면을 계산하여, Anomaly Detection
- 구의 중심에 멀수록 비정상이고, 구의 중심에서 가까울수록 정상 데이터라고 판단함
(2) Isolation Forest
- Random Forest 모델의 Anomaly Detection 버전
- 정상/비정상을 가르는 기준은 해당 데이터를 isolation하는 데 걸린 평균 분기 횟수
- 정상 데이터는 밀집 지역에 분포하고, 비정상 데이터는 그로부터 떨어진 밀도가 낮은 지역에 분포할 것이라는 가정
- 분기 횟수가 적을수록 비정상, 분기 횟수가 높을수록 정상 데이터라고 판단

(3) Clustering
- 가장 기본적으로 KNN 기반 AD(Anomaly Detection) 방법론이 있음
- 정상/비정상을 가르는 기준은 K개의 이웃들과의 거리임
- 정상 데이터는 밀집 지역에 분포하므로 그 거리가 작을 확률이 높고, 비정상 데이터는 클 확률이 높음
- 거리를 계산하는 방법은 Weighted Mean, Max, Mean 등 다양하게 존재하며, 각 방법마다 장/단점이 있음
- Clustering 모델이 갖는 한계점으로는, 데이터가 매우 많은 경우, Computational cost 발생
(4) AE(AutoEncoder) 계열
- AE는 Encoder와 Decoder로 구성되어 있고,
- Encoder는 차원을 축소하여 Vector Z를 생성하고, Decoder를 Z로부터 다시 원본 데이터를 복원하는 역할을 함 (그림 출처)

- 그 자체로 AD 모델로 활용되거나, Hybrid 모델의 Feature Extractor Model로 활용됨
A. 그 자체로 AD 모델
- AE의 Loss 함수인 Reconstruction Error 값이 정상/비정상을 나누는 기준 값이 됨
- 즉, 정상인 경우 AE 모델이 데이터를 잘 복원할 것이기 때문에 Reconstruction Error가 낮을 것이고, 비정상일 경우에는 높을 것
B. Hybrid 모델의 Feature Extractor Model
- 정상/비정상 데이터의 Reconstruction Error에 차이가 미미하더라도 AE모델이 둘을 분명히 구분짓는 Feature를 추출할 수 있음
- 따라서 이 경우에는, Z 벡터를 다른 머신러닝 모델의 인풋으로 사용하면 더 높은 탐지 성능을 기대할 수 있음
- AE의 경우는 데이터셋의 형태에 따라 아래와 같이 단일 혹은 Hybrid로 활용

(5) Word2Vec 계열
- 자연어 임베딩에서 가장 기본적인 모델
- 앞뒤 K개의 단어를 현재 단어를 통해 예측하여 해당 단어를 고정 길이의 Vector로 임베딩함 (그림 출처)
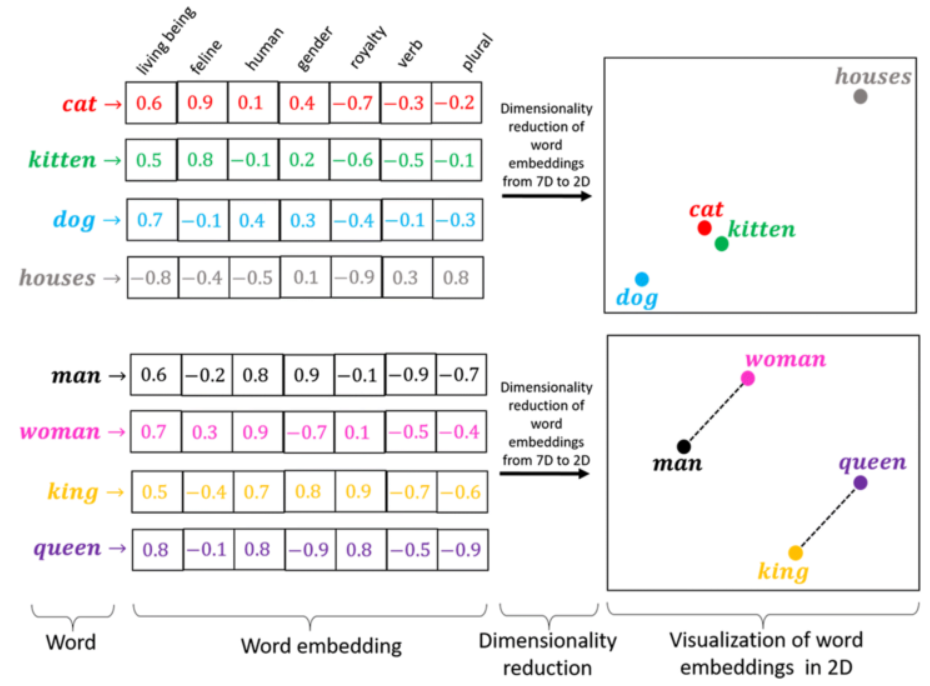
- Word2Vec과 같은 임베딩 계열의 모델은 Sequence 데이터 셋에 대해 Hybrid Model의 Feature Extractor 역할을 할 수 있음
(6) GAN(Generative Adversarial Networks) 계열
- 이미지 Generation 모델로, G(Generator)와 D(Discriminator)로 구성됨
G = Fake 데이터 생성
D = Normal과 Fake 구분지음
-> G와 D가 경쟁적인 관계를 가지도록 설계 (그림 출처)

- 해당 구조는 다음과 같이 AD에 응용 가능함 (ex. ANOGAN)
A. 정상 데이터를 Generation하도록 정상 데이터만을 가지고 G와 D를 학습함 (Existing GAN)
B. G와 D의 파라미터를 고정한 후, 정상 데이터셋과 가장 유사한 G(Z)의 Z를 학습을 통해 찾음
C. 해당 Random Vector Z로부터 생성된 G(Z)와 input X를 비교하여 정상/비정상을 판단함
(7) Deep SVDD (AD만을 위해 개발된 모델)
- SVDD 개념을 응용하여 딥러닝 학습에 적용함

- 데이터들이 중심으로부터 가까워지도록 학습되면서, 모델의 파라미터인 W(가중치)를 제한함으로써, 정상과 비정상을 구분
- Hybrid 모델과 달리 End-to-end Traning이 가능하다는 것이 장점
- Feature Extractor가 AD 수행 과정에 적합하도록 설계되어 학습이 진행되는 모델
(8) Self-Supervised Learning (paper 외)
- SSL은 Input의 라벨 정보 없이 Input의 내재된 특징을 학습할 수 있는 Sub Task를 의미함
- 라벨 정보 없이 학습할 수 있기 때문에 AD task에도 활용될 수 있음


- Paper "A Unified Framework for Self-Supervised Outlier Detection" - OOD Detecton Task에서 SSL의 높은 성능
- A Unified Framework for Self-Supervised Outlier Detection (2021)

3. Application
1) Intrusion Detection
- Intrusion Detection은 사이버 보안 분야에서 요구되는 Task로, 시스템 이상 행위를 탐지하는 것을 의미
- 사용자의 행위를 기록한 시스템 로그가 데이터셋
- 전체 데이터셋이 가변적인 길이의 Sequence 데이터로 구성되어 있음
- Contexture or Conditional Anomaly의 좋은 예시임

- 모든 시스템 로그는 단일 단위로 보면 비정상이라고 볼 수 없고, 맥락 정보를 함께 고려했을 때 그 여부를 판단 가능
- 전문가 기반의 Pattern Matching 방식이 전통적임
- 그래서, 비정상 Pattern에 대한 정보를 알고 있어야 함
- 즉, 새로운 비정상 데이터에 대해서는 작동하지 않을 가능성이 매우 높음
- DAD(Deep AD)는 정상 데이터를 학습하기 때문에, 새로운 비정상 데이터에 대해서도 작동할 수 있음


- 해당 분야의 AD 모델에 있어서 어려운 점은 시간이 지남에 따라 새로운 유형의 정상 패턴이 생겨날 수 있다는 것
- 기존 DAD 입장에서는 새로운 유형의 정상 패턴 또한 AD로 판단할 확률이 있음
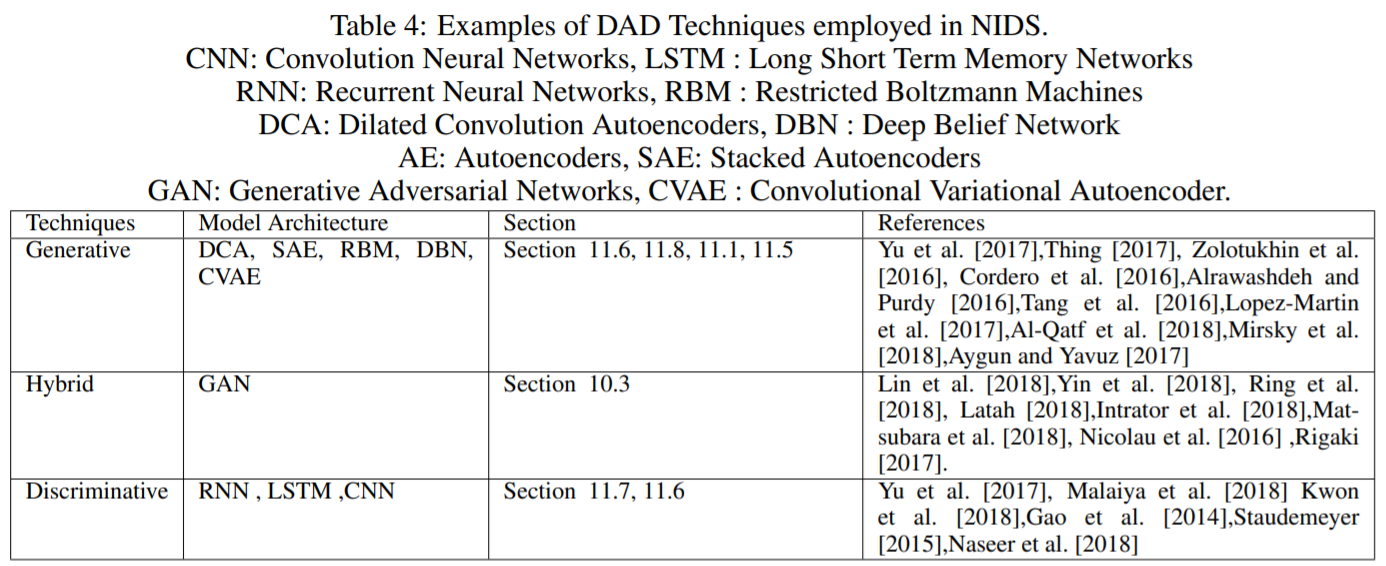
- 시스템 로그에 대해서는 아래와 같은 모델을 활용
- log 데이터셋의 사용 가능한 DAD 모델로는 아래 후보가 존재함
(1) RNN 계열(LSTM, GRU 등), AE 모델을 통한 AD Model
(2) RNN 계열(LSTM, GRU 등) + AE 모델을 통한 Hybrid Model
(3) Word2Vec과 같은 자연어 임베딩 모델을 통한 Hybrid Model

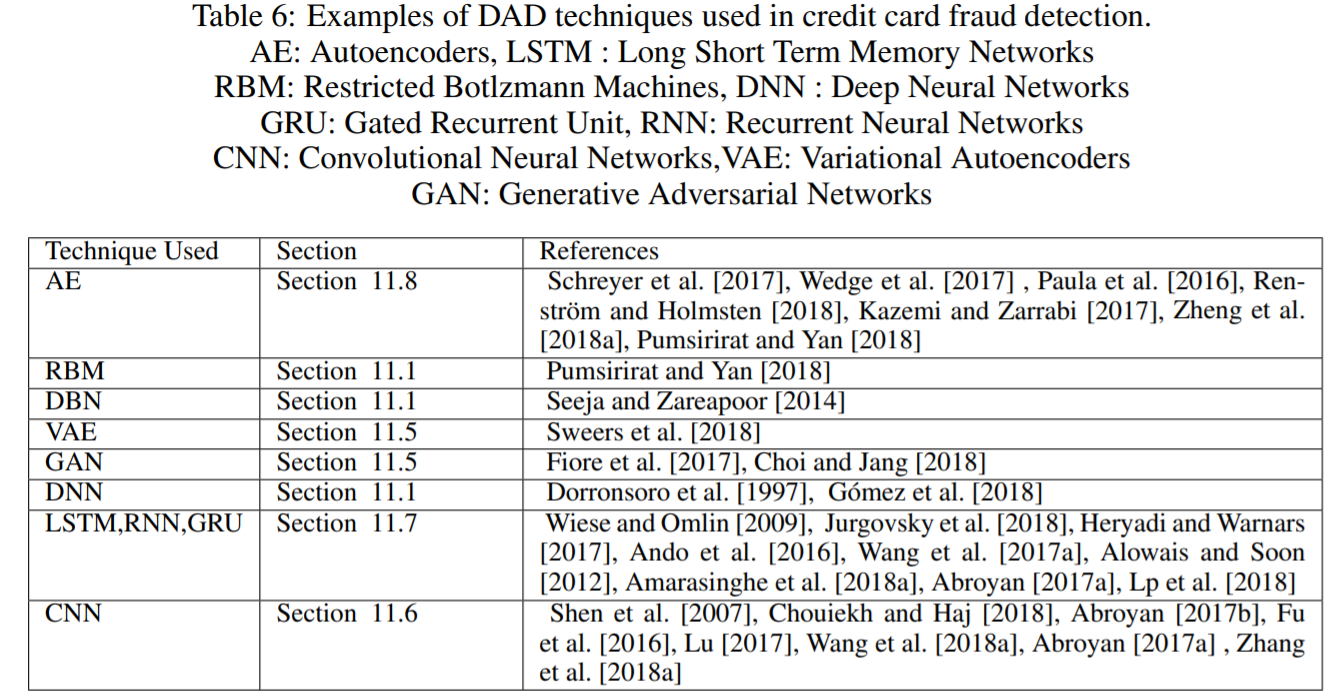
2) Fraud Detection
- Fraud(사기) Detection은 법에 저촉되는 행위에 대한 AD를 의미함
- 다양한 산업군에서 발생할 수 있으며, 대표적으로 Banking, Insurance FD 등이 존재
- 대부분 AD의 유형이 Point Anomaly이고, 정형 데이터인 경우가 많음
- 따라서 대부분의 머신러닝 및 딥러닝 Hybrid 모델을 사용할 수 있음
3) Medical Anomaly Detection
- Medical Anomaly Detection은 의료 산업에서의 AD
- 일반적으로 환자의 병을 진단하기 위한 진료 기록, 진료 영상(혹은 이미지) 등의 데이터셋을 활용함
- 새로운 유형의 질병보다는 이미 알려진 질병을 탐지하는 것이 목적이기 때문에, 지도 학습이 가능한 경우가 많음
- 기존 딥러닝 모델의 경우 판단 근거를 알 수 없는 black box model이기 때문에, 해석가능한 모델에 대한 연구가 활발
4) Industrial Anomaly Detection
- 일반 산업에서의 AD로 굉장히 범위가 넓음
- 일반적으로 공정 센서 데이터가 AD를 위한 데이터 셋이기 때문에 정형 데이터인 경우가 많음
- 또한 공정은 계속 진행되는 것이기 때문에 시계열 데이터인 경우가 많음
- 많은 산업 분야에서 이미 AD가 발생하면 손실이 발생하기 때문에 AD가 발생하기 전 징조를 탐지하는 것이 목표
- 따라서, 이상치 그 자체를 탐지하는 일반적인 AD에 비해 이상 징후를 탐지해야 하는 경우 난이도가 높아짐
5) AD in Time Series
- 시계열 데이터이기 때문에 모델 선택에 제약이 큼, 즉 시계열을 고려할 수 있는 모델을 선택해야 함
- 딥러닝 모델의 경우, RNN 계열(LSTM, GRU)의 모델과 결합하여 자주 사용됨
- Ex. LSTM-AE, CNN-LSTM 등
- Conditional or Contexture Anomaly가 자주 발생함
- 시계열 데이터는 크게 Univariate와 Multivariate 시계열 데이터로 나눌 수 있음
A. Univariate (단변량 시계열 데이터)
- 국제 유가, 주식 가격, 전력 수요 등이 단변량 시계열의 대표적인 예시
B. Multivariate (다변량 시계열 데이터)
- 일반적으로 공정 센서 데이터가 다변량 시계열인 경우가 많음
6) Video Surveillance
- 일반적으로 CCTV 영상 데이터를 통한 AD Task를 의미함
- 치안과 관련한 사람의 이상 행위를 탐지하는 것이 주 목적
- 폭력, 갈취, 위급 상황 등을 탐지하여 도시 안전과 치안에 큰 도움을 줄 수 있음
- Video 데이터셋이기 때문에, CNN, RNN계열의 딥러닝 모델이 주로 활용됨 (Ex. CONVLSTM)
- AD를 하기 위해서는 모델이 영상 안의 객체의 행위를 인식할 수 있어야 하기 때문에, 딥러닝 모델과 혼합되어 사용됨
* Paper reviewed here:
https://arxiv.org/pdf/1901.03407.pdf
* This Video helped me review:
'Data Science > Paper Review' 카테고리의 다른 글
| Deep Semi-Supervised Anomaly Detection (0) | 2022.01.14 |
|---|
댓글