# 홀로서기 기획 연재물은 최근 개인 프로젝트를 진행하면서 겪은 어려움들을 기록한 지극히 개인적인 콘텐츠입니다.
R^2, R-squared, 결정계수, 그게 뭔데.
지난 시간에 필자는 기본 회귀모델(Linear Regression)을 포함해서, Lasso, Ridge, ElasticNet까지 모두 돌려봤었다. 회귀 모델이 정규분포일 때 가장 성능이 좋다는 것을 간과하면 안 된다는 점을 깨닫고 Log Transformation(홀로서기 #05)까지 했었는데, 결국 R-sqaured 값은 쓸만하지 못했다. 다시 한번 살펴보면 아래와 같았다.

대체 '결정계수'라고 불리우는 R^2 값의 정체는 무엇일까. 데이터를 잘 정리해서 모델을 돌려도, 이 모델이 정말 유효한 모델인지 판단하는 데에는 '통계학적 지식'이 매우 중요하다는 생각을 요즘 들어 느낀다. - 덕분에 최근에 통계 공부를 시작했다.. 비록 독학일지라도.. 결정계수(R2)란, 추정한 선형 모형이 주어진 자료에 적합한 정도를 측정하는 척도이다. 적합한 정도?라는 말이 무엇인지 아래 그림을 보면 이해가 쉬울 것 같다.
The better the linear regression (on the right) fits the data in comparison to the simple average (on the left graph), the closer the value of is to 1. The areas of the blue squares represent the squared residuals with respect to the linear regression. The areas of the red squares represent the squared residuals with respect to the average value. - Wikipedia
- R^2 값은 1에서 (SSR / SST)를 뺀 값이다.
- SST(Total)는 좌측 그림에서 점(실제값)에서 y의 평균까지의 차이의 제곱, 즉 Y의 전체 변동성의 정도
- SSR(Residual)은 우측 그림에서 점(실제값)에서 회귀선(예측값)까지의 차이의 제곱, 즉 모형에 의해 발생되는 변동성의 정도
- (SSR / SST) = 예측 모형의 편차가 전체 데이터의 편차를 모두 대신할 수 있는가? = 대신할 수 있다면 '0'이 됨
- 따라서, R^2의 의미는 변수가 되는 '특성(Feature)'이 모델의 결과물인 '종속변수, 타겟(Target)'을 얼마나 설명하는가?
- 0과 1 사이의 값을 가지고, 1에 가까울수록 모델이 더 잘 설명된다는 말이다.
- 하단 그림 출처
alpha 값을 바꿔서 모델을 바꿔보자.
결정계수 R^2가 경우에 따라 다르지만, 일반적으로 0.7~0.8 이상은 되어야 모델이 유효/유용하다는 판단을 내린다고 알려져 있다. 현재 프로젝트의 모델링 상에서, 모델의 결정계수를 향상시키기 위해서 손쉽게 튜닝할 수 부분으로는 '흔히 alpha 값을 조정'할 수 있다. 우리가 직접 정해줘야 하는 값을 '하이퍼파라미터'라고도 한다. 기존에 수행한 회귀 모델은 모두 alpha를 1로 설정했었다. 이번에는 alpha=0.5, alpha=0.1로 바꿔서 다시 학습해봤다.
cf) alpha의 의미
- 얼마나 제약(L1_ridge, L2_lasso)을 할 것인가의 문제
- scikit-learn.org documentation
alpha = 0 is equivalent to an ordinary least square, solved by the LinearRegression object. For numerical reasons, using alpha = 0 with the Lasso object is not advised. Given this, you should use the LinearRegression object.
1) alpha=0.5
# Linear Regression Fitting
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
reg.fit(X_train_ss, y_train)
# Lasso(L1)
from sklearn.linear_model import Lasso
las = Lasso(alpha=0.5)
las.fit(X_train_ss, y_train)
# Ridge(L2)
from sklearn.linear_model import Ridge
rid = Ridge(alpha=0.5)
rid.fit(X_train_ss, y_train)
# ElasticNet
from sklearn.linear_model import ElasticNet
en = ElasticNet(alpha=0.5, l1_ratio=0.5)
en.fit(X_train_ss, y_train)
# Prediction
pred_reg = reg.predict(X_test_ss)
pred_las = las.predict(X_test_ss)
pred_rid = rid.predict(X_test_ss)
pred_en = en.predict(X_test_ss)
# R-sqaured
from sklearn.metrics import r2_score
print('------------- R-sqaured -------------')
print(f'Linear Regression : {r2_score(y_test, pred_reg):.6f}')
print(f'Lasso : {r2_score(y_test, pred_las):.6f}')
print(f'Ridge : {r2_score(y_test, pred_rid):.6f}')
print(f'ElasticNet : {r2_score(y_test, pred_en):.6f}')
# MSE
from sklearn.metrics import mean_squared_error
print('------------- MSE -------------')
print(f'Linear Regression : {mean_squared_error(y_test, pred_reg):.6f}')
print(f'Lasso : {mean_squared_error(y_test, pred_las):.6f}')
print(f'Ridge : {mean_squared_error(y_test, pred_rid):.6f}')
print(f'ElasticNet : {mean_squared_error(y_test, pred_en):.6f}')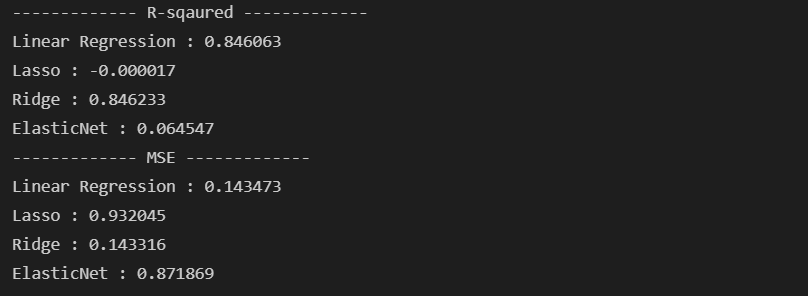
2) alpha=0.1
# Linear Regression Fitting
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
reg.fit(X_train_ss, y_train)
# Lasso(L1)
from sklearn.linear_model import Lasso
las = Lasso(alpha=0.1)
las.fit(X_train_ss, y_train)
# Ridge(L2)
from sklearn.linear_model import Ridge
rid = Ridge(alpha=0.1)
rid.fit(X_train_ss, y_train)
# ElasticNet
from sklearn.linear_model import ElasticNet
en = ElasticNet(alpha=0.1, l1_ratio=0.5)
en.fit(X_train_ss, y_train)
# Prediction
pred_reg = reg.predict(X_test_ss)
pred_las = las.predict(X_test_ss)
pred_rid = rid.predict(X_test_ss)
pred_en = en.predict(X_test_ss)
# R-sqaured
from sklearn.metrics import r2_score
print('------------- R-sqaured -------------')
print(f'Linear Regression : {r2_score(y_test, pred_reg)}')
print(f'Lasso : {r2_score(y_test, pred_las)}')
print(f'Ridge : {r2_score(y_test, pred_rid)}')
print(f'ElasticNet : {r2_score(y_test, pred_en)}')
# MSE
from sklearn.metrics import mean_squared_error
print('------------- MSE -------------')
print(f'Linear Regression : {mean_squared_error(y_test, pred_reg)}')
print(f'Lasso : {mean_squared_error(y_test, pred_las)}')
print(f'Ridge : {mean_squared_error(y_test, pred_rid)}')
print(f'ElasticNet : {mean_squared_error(y_test, pred_en)}')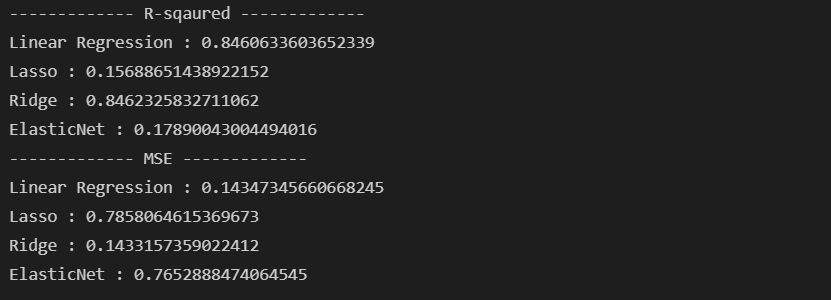
하하. +값은 됐는데, 쓸만한 수준은 아니구나. 결국 LR 수준(alpha가 매우 작아져야)으로 가야지만 결국 쓸만한 모델이 되는 듯하다. 선형 모델과 Ridge 모델은 MSE도 그렇고 매우 쓸만한 수준인 듯하다. 내년 봄을 겨냥해서 이번 해의 수요량을 활용해 학습했는데, LR 모델이나 Ridge 모델을 활용하면 될 듯하다. 2022년 봄의 자전거 대여량 데이터가 공개되면 모델에 한번 넣어 보아야겠다.

AWS부터 SQL, EDA, Visualization, ML Regression 까지 전체 과정을 스스로 홀로서기 해봤다.
일주일에 한번씩 정리하는 과정에서 굉장히 많은 것들을 공부한 느낌이 들었다.
개인 프로젝트를 작지만 스스로 해내는 과정이 매우 필요하다는 생각이 들었던 과정이었다.
앞으로 소홀히 하지 않고 개인 프로젝트를 꾸준히 해 나가야겠다.
Bicycle project, The End! 홀로서기 #6 끝.
'Data Science > Project' 카테고리의 다른 글
| [홀로서기 #08] 이상 탐지(Anomaly Detection) 베이직. (0) | 2022.07.13 |
|---|---|
| [홀로서기 #07] 80 Features, 8M Records... Pandas 말고 Dask! (1) | 2022.01.19 |
| [홀로서기 #05] 회귀 모델링 하기 전에 꼭 확인하기 (2) - 타겟 분포 (Log Transformation) (0) | 2022.01.03 |
| [홀로서기 #04] 회귀 모델링 하기 전에 꼭 확인하기 (1) - 범주형 특성 변수(Categorical Features) (0) | 2021.12.28 |
| [홀로서기 #03] SQL EDA, Python으로 쉽게 시각화하기 (0) | 2021.12.21 |




댓글