# 홀로서기 기획 연재물은 최근 개인 프로젝트를 진행하면서 겪은 어려움들을 기록한 지극히 개인적인 콘텐츠입니다.
무작정 모델링 하기
지난 시간(OneHotEncoding: 홀로서기 #04)에 이어서 본격적으로 모델링을 진행했다. 결론부터 말하자면, 모델 성능은 처참했다. 꼭 확인해주어야 하는 부분을 확인해주지 않고 넘어갔기 때문인데, 그 부분은 뒷부분에서 확인할 수 있다.
회귀모델에 대표적으로 Linear Regression 이 있고, 각 제약식을 어떻게 주느냐에 따라서, Ridge, Lasso, ElasticNet으로 분화된다. 기본적인 회귀 분석에는 제약식이 포함될 수 있는데, 제약이 없으면 우리가 추정하려는 가중치 w가 폭발적으로 커질 수 있고, 이로 인해서 분산이 커지는 문제가 발생할 수 있다. 이런 문제를 개선하기 위해서 제약식을 사용하게 된다. L2 제약식을 두면 Ridge(릿지) 회귀라고 하고, L1 제약식을 두면 Lasso(라쏘) 회귀라고 한다. 그리고 ElasticNet(엘라스틱넷)은 릿지와 라쏘를 합쳐 놓은 형태이다. 자세한 내용은 아래 sklearn 공식 문서를 참조하면 좋다.
- sklearn.linear_model.Lasso 공식 문서
- sklearn.linear_model.Ridge 공식 문서
- sklearn.linear_model.ElasticNet 공식 문서
일단 무작정 모델링을 해보자. 아래는 전체 코드를 가져왔다.
# feature : 요일(onehot), 대여소(onehot), 날씨
# target : 대여수(count)
X = final.drop(columns=['count', 'month', 'day', 'dayofweek', 'stop'])
y = final['count']
print(X.shape, y.shape)
# Train, Test
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
# Standard Scaler
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(X_train)
X_train_ss = ss.transform(X_train)
X_test_ss = ss.transform(X_test)
# Linear Regression Fitting
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
reg.fit(X_train_ss, y_train)
# Lasso(L1)
from sklearn.linear_model import Lasso
las = Lasso(alpha=1)
las.fit(X_train_ss, y_train)
# Ridge(L2)
from sklearn.linear_model import Ridge
rid = Ridge(alpha=1)
rid.fit(X_train_ss, y_train)
# ElasticNet
from sklearn.linear_model import ElasticNet
en = ElasticNet(alpha=1, l1_ratio=0.5)
en.fit(X_train_ss, y_train)
# Prediction
pred_reg = reg.predict(X_test_ss)
pred_las = las.predict(X_test_ss)
pred_rid = rid.predict(X_test_ss)
pred_en = en.predict(X_test_ss)
# R-sqaured
from sklearn.metrics import r2_score
print(f'Linear Regression : {r2_score(y_test, pred_reg)}')
print(f'Lasso : {r2_score(y_test, pred_las)}')
print(f'Ridge : {r2_score(y_test, pred_rid)}')
print(f'ElasticNet : {r2_score(y_test, pred_en)}')
# MSE
from sklearn.metrics import mean_squared_error
print(f'Linear Regression : {mean_squared_error(y_test, pred_reg)}')
print(f'Lasso : {mean_squared_error(y_test, pred_las)}')
print(f'Ridge : {mean_squared_error(y_test, pred_rid)}')
print(f'ElasticNet : {mean_squared_error(y_test, pred_en)}')- 모델링 과정은 다음과 같다.
1) 최종 데이터셋에서 Feature와 Target을 나눠서 변수로 놓고 Test/Train 데이터를 8:2로 나눴다.
2) 각각 Standard Scaler를 취했다. 여기서 주의할 점은 Train 데이터로 SS를 fit해주고, 그걸로 Test도 취해줘야 한다.
3) 기본 선형회귀인 Linear Regression 과 제약 모델인 Lasso, Ridge, ElasticNet을 학습시켰다. (Default alpha : 1)
4) 예측을 수행하고, R-Squared와 MSE를 확인했다.

보통은 이 정도만 갖춰서 돌려도, 적절한 모델 성능이 나오는 경우가 많다. 나의 경우는 매우 좋지 않은 성능을 보였다.. R-squared (결정계수)는 Lasso와 ElasticNet을 제외하고는 쓸만하게 나왔는데.. MSE 무슨 일인데..? 문제가 무엇인지 다시 처음으로 돌아가서 데이터를 살펴보았다.
Target의 분포를 꼭 확인하자.
EDA에서 필자가 놓친 부분은, 타겟의 분포를 확인하지 않은 것이다. 회귀 모델링 결과는 타겟(Target) 분포가 정규분포 형태를 띄어야 성능이 높은 것으로 통계적으로 알려져 있다. 이 부분을 놓쳐서 성능이 매우 좋지 않게 나왔다는 것을 알았다.
# 대여건수(Count) 분포 확인
import seaborn as sns
plt.title('Original distplot for count')
sns.distplot(final['count'])
plt.show()이럴 때 이용하는 것이, Log Transformation이다. 타겟의 값들을 log를 취해주면 정규분포 형태로 바뀌는 효과를 볼 수 있다. 변환에는 넘파이(numpy)의 log1p 함수를 활용했다.
# Log Transformation
import numpy as np
plt.title('Log Transformed distplot for count')
y_log = np.log1p(final['count'])
sns.distplot(y_log)
plt.show()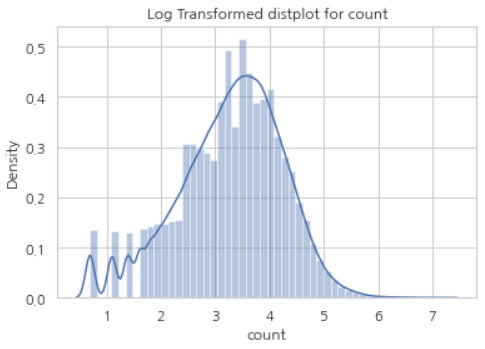
로그 변환한 타겟을 y로 놓고 다시 모델링을 시도했다. 결과는 아래와 같다.
# y_log
X = final.drop(columns=['count', 'month', 'day', 'dayofweek', 'stop'])
y = y_log
print(X.shape, y.shape)
# Train, Test
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
# Standard Scaler
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(X_train)
X_train_ss = ss.transform(X_train)
X_test_ss = ss.transform(X_test)
# Linear Regression Fitting
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
reg.fit(X_train_ss, y_train)
# Lasso(L1)
from sklearn.linear_model import Lasso
las = Lasso(alpha=1)
las.fit(X_train_ss, y_train)
# Ridge(L2)
from sklearn.linear_model import Ridge
rid = Ridge(alpha=1)
rid.fit(X_train_ss, y_train)
# ElasticNet
from sklearn.linear_model import ElasticNet
en = ElasticNet(alpha=1, l1_ratio=0.5)
en.fit(X_train_ss, y_train)
# Prediction
pred_reg = reg.predict(X_test_ss)
pred_las = las.predict(X_test_ss)
pred_rid = rid.predict(X_test_ss)
pred_en = en.predict(X_test_ss)
# R-sqaured
from sklearn.metrics import r2_score
print(f'Linear Regression : {r2_score(y_test, pred_reg)}')
print(f'Lasso : {r2_score(y_test, pred_las)}')
print(f'Ridge : {r2_score(y_test, pred_rid)}')
print(f'ElasticNet : {r2_score(y_test, pred_en)}')
# MSE
from sklearn.metrics import mean_squared_error
print(f'Linear Regression : {mean_squared_error(y_test, pred_reg)}')
print(f'Lasso : {mean_squared_error(y_test, pred_las)}')
print(f'Ridge : {mean_squared_error(y_test, pred_rid)}')
print(f'ElasticNet : {mean_squared_error(y_test, pred_en)}')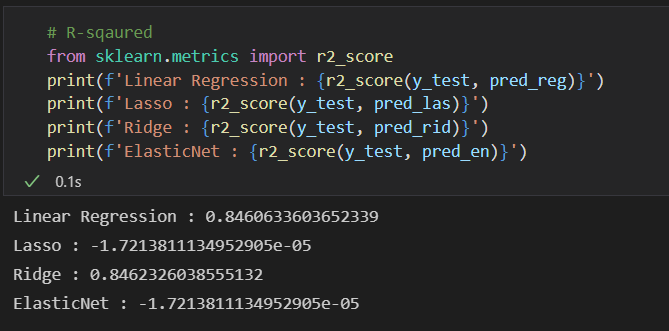
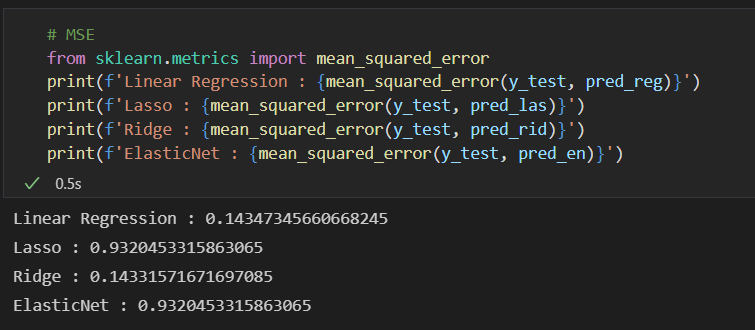
확실히 성능이 좋아진 것을 알 수 있다. 아직까지 쓸만한 느낌은 아니지만(왜냐하면 Lasso와 ElasticNet의 R-Squared 값을 개선할 필요가 있어보이기 때문에) 타겟의 분포가 이렇게나 중요하다는 사실을 다시 한번 깨달았다.
EDA에서 꼼꼼히 데이터를 살펴볼 필요가 있다는 것을 다시 깨달은 좋은 시간이었다.
위에서 봤듯이, 라쏘와 릿지, 엘라스틱넷 등 제약모델도 기본 회귀모형과 비교했을 때 현저히 다름을 알 수 있다.
다음 시간에는 alpha 값 등 하이퍼파라미터를 조정해서 모델 성능이 어떻게 달라지는지 알아볼 예정이다.
오늘 프로젝트도 고생했다. 홀로서기 #5 끝.
'Data Science > Project' 카테고리의 다른 글
| [홀로서기 #07] 80 Features, 8M Records... Pandas 말고 Dask! (1) | 2022.01.19 |
|---|---|
| [홀로서기 #06] 회귀 Regression 결정계수(R^2), 알파(alpha) (0) | 2022.01.11 |
| [홀로서기 #04] 회귀 모델링 하기 전에 꼭 확인하기 (1) - 범주형 특성 변수(Categorical Features) (0) | 2021.12.28 |
| [홀로서기 #03] SQL EDA, Python으로 쉽게 시각화하기 (0) | 2021.12.21 |
| [홀로서기 #02] SQL 대량 데이터, VIEW로 핸들링하기 (0) | 2021.12.14 |




댓글