데이터 정리
- 우리가 사용할 데이터프레임 crime_anal_station 은 다음과 같다.
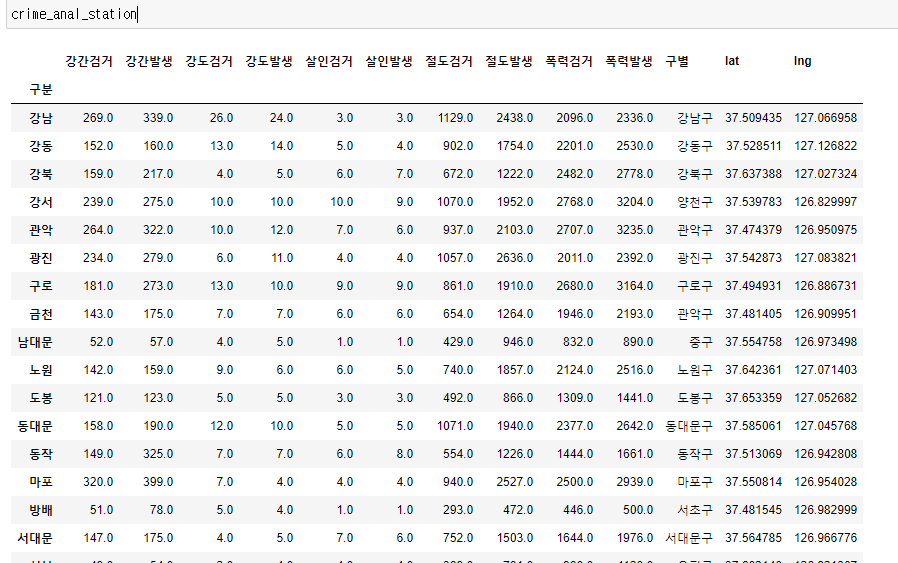
- 일단 해당 데이터를 활용해서, '구별'을 인덱스로 하여, 값의 합계를 나타낸 피봇테이블을 만들었다.
crime_anal_gu = crime_anal_station.pivot_table( #여기서 pd.pivot_table(crime_anal_station, ~ 으로 시작해도 된다.
index="구별",
aggfunc=np.sum,
)
- 여기서 우리는 lat, lng 컬럼이 필요가 없기 때문에, 삭제한다. (drop()을 활용했다.)
crime_anal_gu.drop(["lat", "lng"], axis=1, inplace=True)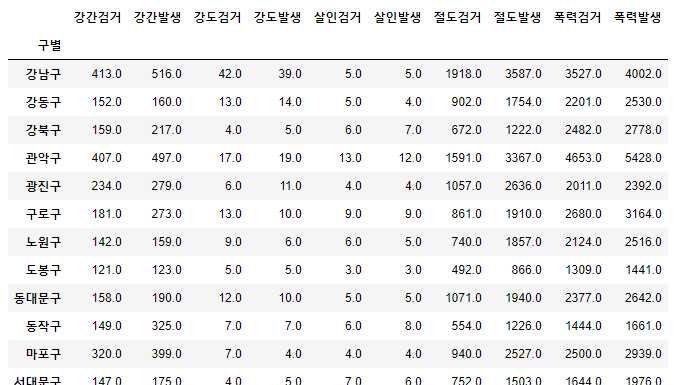
- 우리가 궁금한 수치는, 각 범죄별 '검거율'이다. 예를 들면 살인의 검거율 = 살인검거의 값 / 살인발생의 값이 될 것이다.
- 이때 다중 컬럼을 다중 컬럼으로 나눠주는 기능을 하는 .div()을 활용하면 좋다.
num = ["강간검거", "강도검거", "살인검거", "절도검거", "폭력검거"] # 분자 컬럼명
den = ["강간발생", "강도발생", "살인발생", "절도발생", "폭력발생"] # 분모 컬럼명
new_column = ["강간검거율,"강도검거율","살인검거율","절도검거율","폭력검거율"]
crime_anal_gu[new_column] = crime_anal_gu[num].div(crime_anal_gu[den].values) *100
# 다중 컬럼으로 나누는 경우에는 뒤에 .values 를 꼭 붙이자
crime_anal_gu.head()
- 검거율 테이블을 살펴보면, 비율인데 100%가 넘는 값들이 있다. 발생보다 검거를 더했다고?
- 그래서 100보다 높은 값들을 100으로 바꿔주는 작업을 해준다.
crime_anal_gu[crime_anal_gu[new_column]>100] = 100
- 또한, 발생 컬럼만 필요하기 때문에, 검거 컬럼은 삭제하고, 발생 컬럼의 이름을 rename 한다.
crime_anal_gu.drop(num, axis=1, inplace=True)
# num = ["강간검거", "강도검거", "살인검거", "절도검거", "폭력검거"]
crime_anal_gu.rename(columns={
"강간발생" : "강간",
"강도발생" : "강도",
"살인발생" : "살인",
"절도발생" : "절도",
"폭력발생" : "폭력",
}, inplace=True) # rename도 inplace해주자.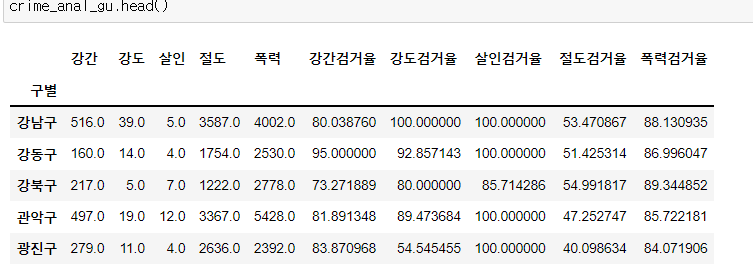
- 범죄 발생 현황 데이터를 보면, 살인이 강도나 절도보다 중범죄에 해당하는 데,
- 시각화를 하면 수치가 작아서 그 중요성이 작게 나타날 가능성이 많다.
- 정규화를 해주자 : (해당 데이터 / 해당 데이터 컬럼의 최댓값)
col = ["강간", "강도", "살인", "절도", "폭력"]
crime_anal_norm = crime_anal_gu[col] / crime_anal_gu[col].max()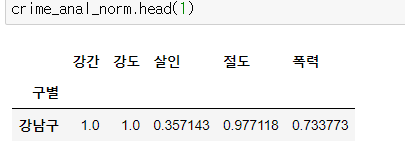
- 해당 데이터 프레임에 인구수, CCTV 소계, 범죄대푯값, 검거대푯갑을 넣어주려고 한다.
- 인구수, CCTV 소계는 다른 데이터프레임을 불러와서 첨부한다.
- 범죄 대푯값은 5대 범죄의 정규화 값들을 평균한 값을 넣어주도록 한다. (np.mean())
- 검거 대푯값은 5대 범죄의 검거 실적을 평균한 값을 넣어주도록 한다.(crime_anal_gu에서 가져옴)
result_CCTV = pd.read_csv("../ds_study/data/01.Seoul CCTV result.csv", index_col=0, encoding="utf-8")
crime_anal_norm["인구수", "CCTV"] = result_CCTV["인구수", "소계"]
col = ['강간', '강도', '살인', '절도', '폭력']
crime_anal_norm["범죄"] = np.mean(crime_anal_norm[col], axis=1) #얘는 axis=1이 가로 축임
col_2=["강간검거율", "강도검거율","살인검거율", "절도검거율", "폭력검거율"]
crime_anal_norm["검거"] = np.mean(crime_anal_gu[col_2], axis=1)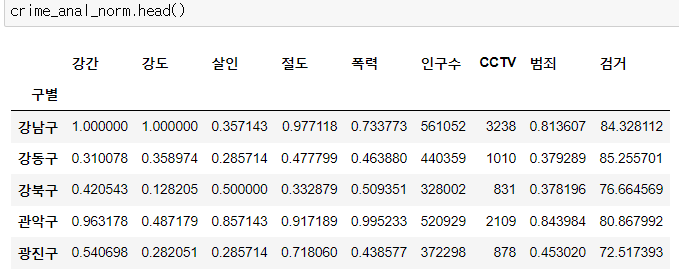
- 해당 데이터를 저장한다.
crime_anal_norm.to_csv("../ds_study/data/02. crime_in_Seoul_final.csv")
seaborn
- matplotlib에도 다양한 시각화 툴이 있지만,
- seaborn은 더 다양하고 다채로운 시각화 요소들이 존재한다.
- 초기 설정은 다음과 같다. (seaborn은 sns로 호출할 수 있도록 한다)
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib import rc
plt.rcParams["axes.unicode_minus"]=False #마이너스 값 오류 방지
rc("font", family="Malgun Gothic") # 폰트는 '맑은고딕'으로
%matplotlib inline # 그림 그리겠음- seaborn에서 그림을 그릴 때는 다음과 같이 기본적인 기능을 활용한다.
tips = sns.load_dataset("tips") # sns에서 기본으로 제공하는 tip 데이터 셋 불러오기
sns.set_style("darkgrid") # 밑바탕 옵션 - darkgrid, whitegird, dark, white, ticks
plt.figure(figsize=(10, 6))
sns.boxplot(x=tips["total_bill"]) # boxplot으로 그리기
plt.show()- seaborn의 boxplot, swarmplot, lmplot, heatmap, pairplot을 차례대로 그려본다.
1) sns.boxplot()
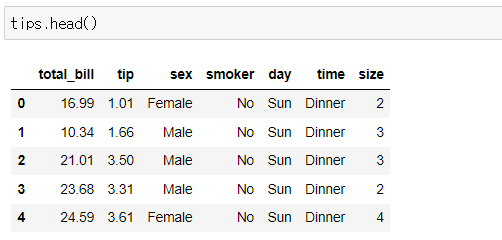
- tips 데이터는 다음과 같다.
- total_bill이 어떤 값을 가지는지 boxplot으로 그려봤다.
plt.figure(figsize=(10,6))
sns.boxplot(x=tips["total_bill"])
plt.show()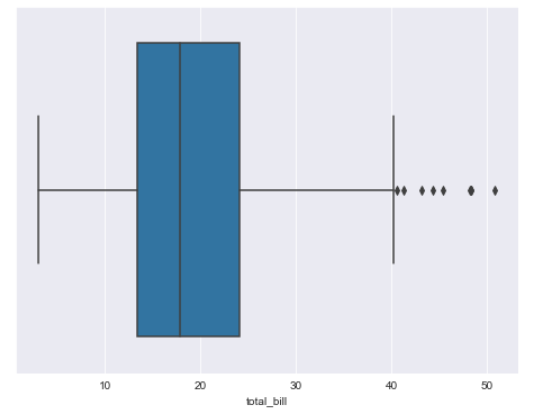
- 요일(day)별로 total_bill을 boxplot으로 그리는데, 흡연 여부로 나누어서(hue=) 시각화하고 싶다면 아래와 같다.
plt.figure(figsize=(8,6))
sns.boxplot(data=tips, x="day", y="total_bill", hue="smoker") # hue는 데이터를 쪼개서 볼 때 유용하다.
plt.show()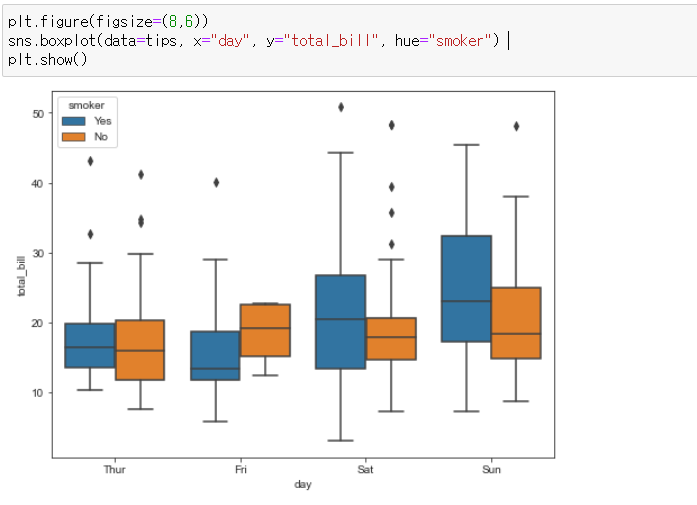
- boxplot의 서식을 바꾸고 싶을 때는 palette="SetN"을 추가한다.
plt.figure(figsize=(8,6))
sns.boxplot(data=tips, x="day", y="total_bill", hue="smorker", palette="Set3")
plt.show()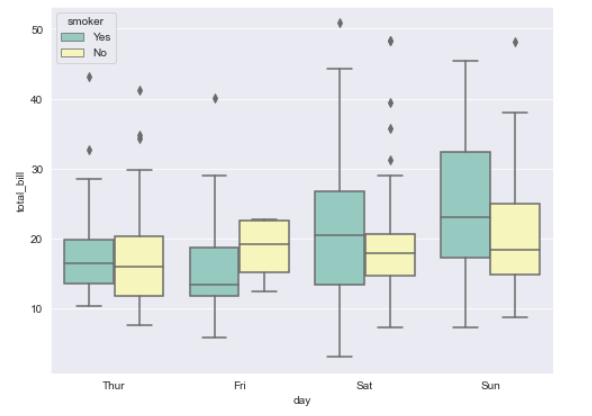
2) sns.swarmplot()
- boxplot을 그린 것과 똑같은 데이터를 넣어서 swarmplot을 그려봤다.
plt.figure(figsize=(8,6))
sns.swarmplot(data=tips, x="day", y="total_bill", hue="smoker", color="0")
# color에 넣는 숫자는 투명도를 의미한다. 0 ~ 1 중에 "1"에 가까울수록 투명
# boxplot도 가능하며, 색이 흑백으로 바뀐다는 단점이 있다.
plt.show()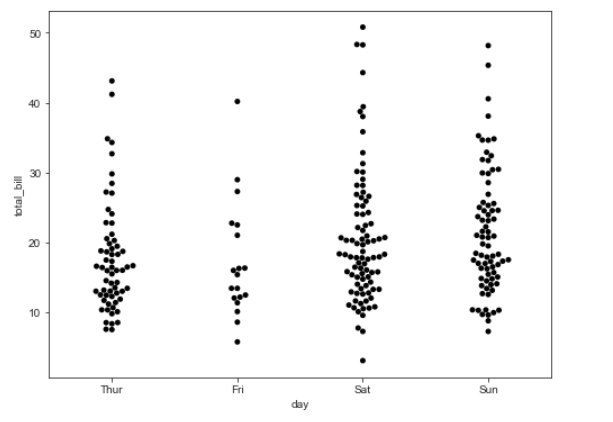
- boxplot과 swarmplot을 함께 그릴 수도 있다. (이럴 때는 swarmplot의 투명도를 높여주면 좋다.)
plt.figure(figsize=(8,6))
sns.boxplot(data=tips, x="day", y="total_bill", palette="Set3")
sns.swarmplot(data=tips, x="day", y="total_bill", color="0.5")
plt.show()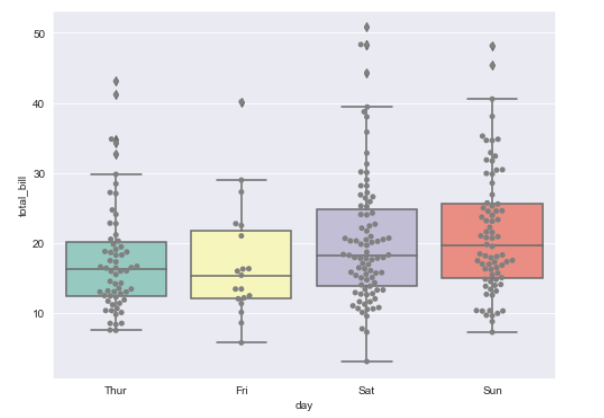
3) sns.lmplot() : 선형회귀선을 함께 그린 것
- x를 total_bill 값으로, y를 tip 값으로 놓고 lmplot을 그렸다.
- lmplot은 특별히, figure(figsize=(a,b))로 그래프 크기를 조정하는 것이 아니라, height를 지정해서 조정한다.
# lmplot은 height로 크기를 조정한다.
sns.lmplot(data=tips, x="total_bill", y="tip", height=10)
plt.show()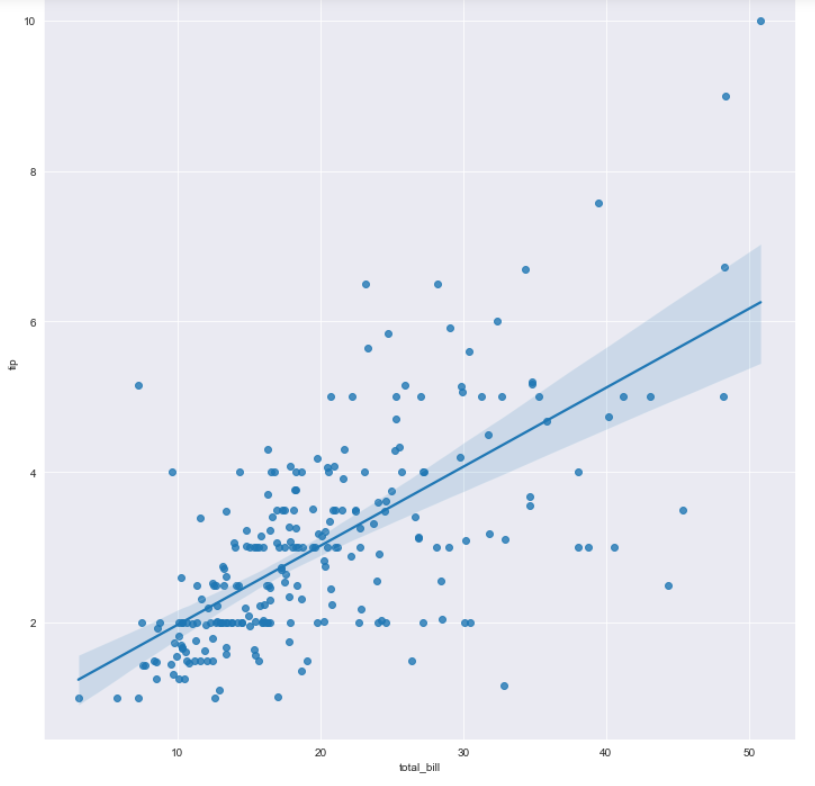
- hue도 넣어서 그릴 수 있다. hue="smoker"로 지정했다.
sns.lmplot(data="tips", x="total_bill", y="tip", hue="smoker", height=10)
plt.show()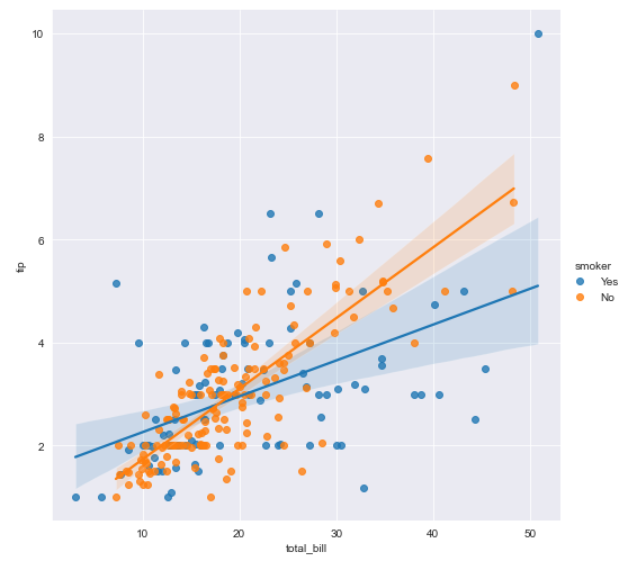
- lmplot은 회귀식을 함께 표시하는 것이라고 배웠다.
- 해당 식의 차수가 증가하거나 아웃라이어를 제외시키는 방법을 익히고자, anscombe 데이터셋을 가져온다.
anscombe = sns.load_dataser("anscombe")
anscombe.head()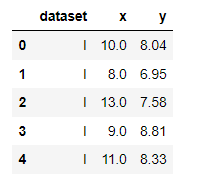
- darkgrid로 스타일을 설정하고,
- anscombe 데이터의 x, y 컬럼을 바탕으로 lmplot을 그린다.
- 이 과정에서 dataset 열의 I 컬럼만 가져오기 위한 쿼리를 작성한다 : .query(" dataset =='I' ")
- 크기는 7로 지정 : height = 7
- 점의 크기는 80으로 지정한다. : scatter_kws={"s":80}
- 신뢰구간을 표시하지 않는다, : ci=None
sns.set_style("darkgrid")
sns.lmplot(
data=anscombe.query("dataset=='I'"),
x="x",
y="y",
ci=None,
scatter_kws={"s":80},
height=7
)
plt.show()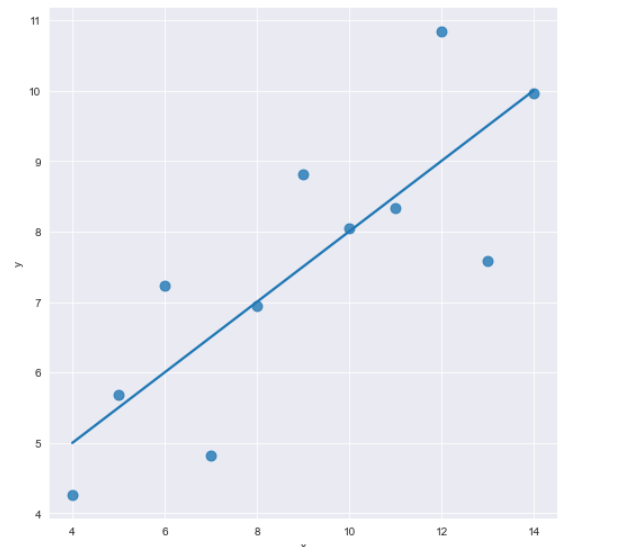
- 다음은 2차식 데이터다. 차수가 올라가면 order로 차수를 표시해준다. 데이터는 dataset=="II"으로 받는다.
sns.set_style("darkgrid")
sns.lmplot(
data=anscombe.query("dataset=='II'"),
x="x",
y="y",
scatter_kws={"s":30},
order=2,
ci=None,
height=7
)
plt.show()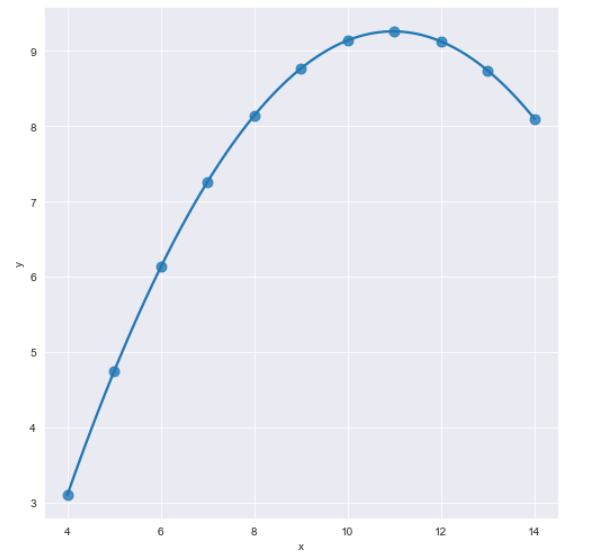
- 다음은 아웃라이어가 있는 그래프이다.
sns.set_style("darkgrid")
sns.lmplot(
data=anscombe.query("dataset=='III'"),
x="x",
y="y",
ci=None,
height=7,
scatter_kws={"s":30}
)
plt.show()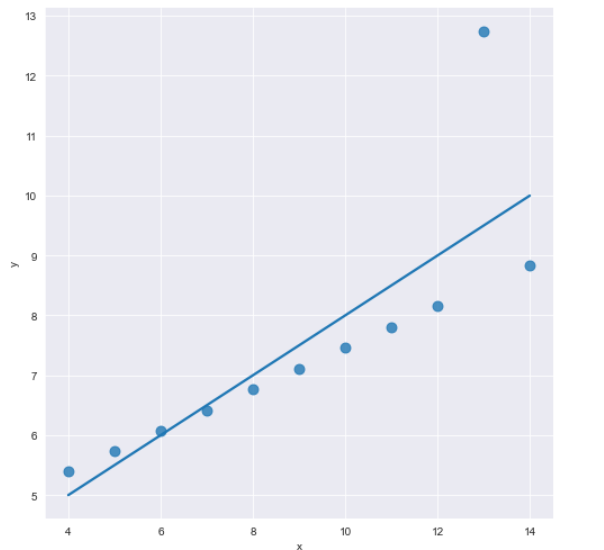
- 아웃라이어(이상점) 때문에 회귀식이 빗나가는 느낌을 준다. -> 이럴 때는 robust=True 옵션을 준다.
sns.set_style("darkgrid")
sns.lmplot(
data=anscombe.query("dataset=='III'"),
x="x",
y="y",
robust=True,
height=7,
scatter_kws={"s":30},
ci=None
)
plt.show()
# 여기서 에러가 난다면, statsmodels이 없는 것이다.
# 윗줄에 pip install statsmodels 를 실행한 후에 하면 실행된다.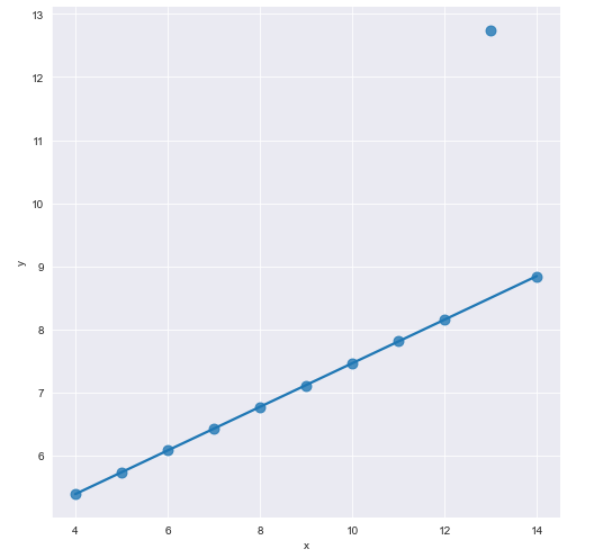
4) sns.heatmap() : 두 변수 사이의 상관관계를 색감으로 표현해주는 그래프
- 히트맵을 그리는 데에는 tips보다 더 적합한 데이터를 적용했다.
- sns가 제공하는 flight 데이터셋을 활용했다.
flights = sns.load_dataset("flights")
flights.head()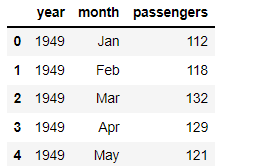
- 이를 바탕으로, 인덱스는 month, 컬럼은 year, 값은 passenger로 하는 pivot table을 그려봤다.
flights = flight.pivot_table(index="month", columns="year", values="passengers")
flights.head()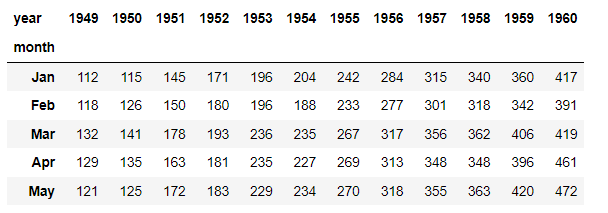
- 이 피봇테이블을 바탕으로, heatmap을 그려보자.
- annot 옵션은 히트맵에 각 값(values)을 표시하는 기능이다.
plt.figure(figsize=(10,6))
sns.heatmap(data=flights, annot=True)
plt.show()- heatmap은 모양만 봐도 알겠지만, 2d 매트릭스만 들어갈 수 있다. x, y는 그려진 대로 알아서 들어간다.
- index, column 한 개씩으로 이루어진 피봇테이블 형태 같은 데이터만 data로 들어갈 수 있다는 말 같다.
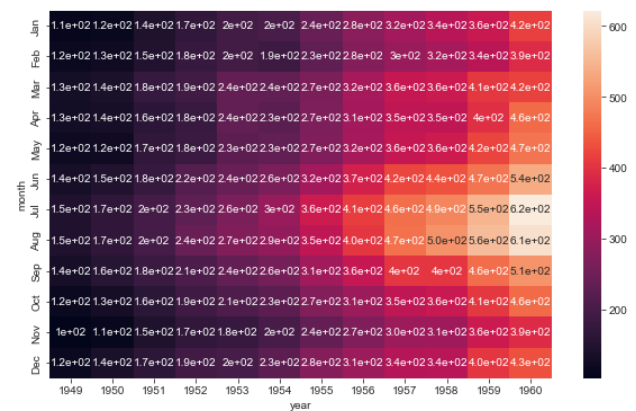
- 여기서 annot 설정을 해줬는데, 숫자들이 정수가 아니라서 보기가 힘들다. 정수 표시는 fmt="d" 로 해준다.
plt.figure(figsize=(10,6))
sns.heatmap(data=flights, annot=True, fmt="d")
plt.show()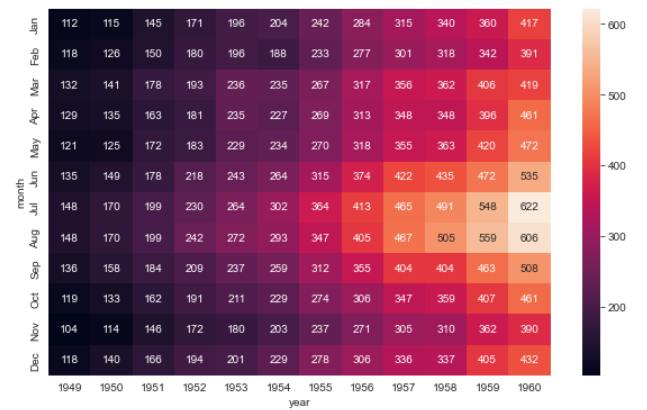
- 컬러가 마음에 들지 않는다면, 컬러맵(cmap) 설정도 해줄 수 있다. "YlGnBu"으로 지정해봤다.
plt.figure(figsize=(10,6))
sns.heatmap(data=flights, annot=True, fmt="d", cmap="YlGnBu")
plt.show()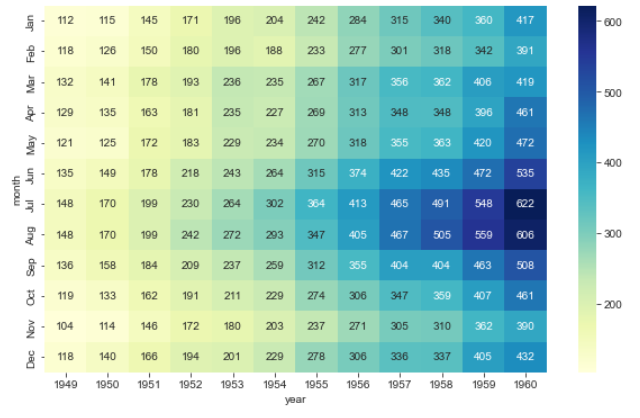
5) sns.pairplot : 상관관계를 보여주는 다양한 시각화 그래프를 보여준다.
- pairpot에는 머신러닝계의 수학의 정석 1장 1절 데이터라고 불린다는 iris 데이터셋을 활용했다.
iris = sns.load_dataset("iris")
iris.tail()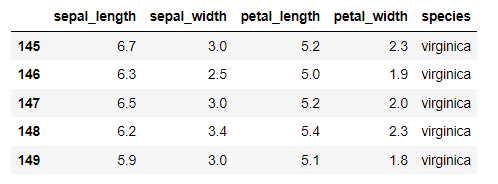
- iris 데이터를 pairplot으로 그려봤다. (pairplot도 height로 크기를 지정한다)
sns.pairplot(data=iris)
plt.show()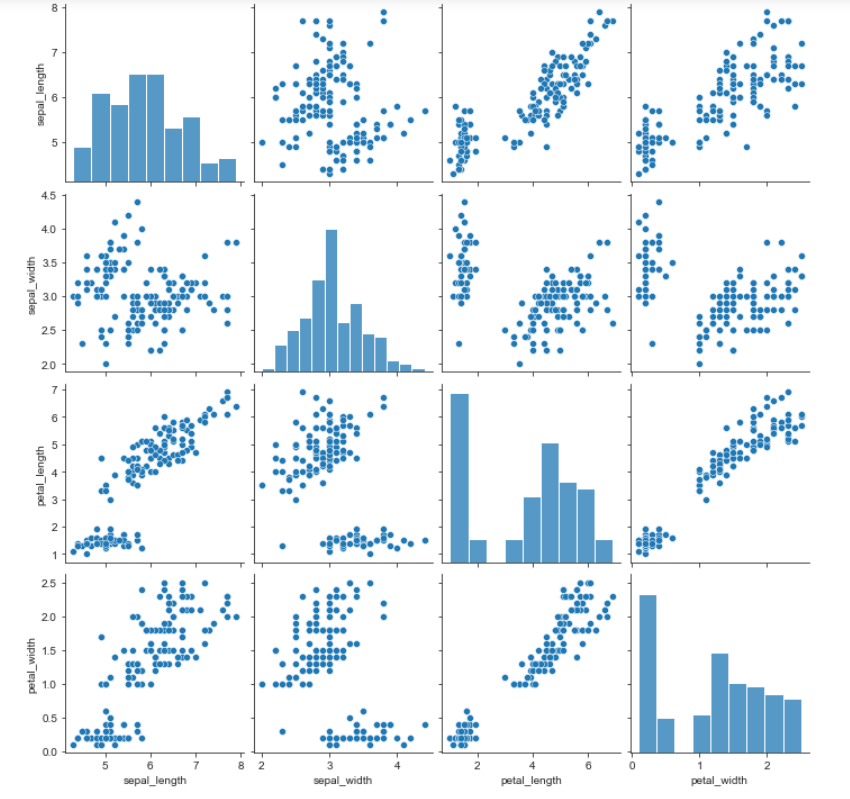
- 결과를 보면 species에 따라서는 구분이 없이 표현되었다. hue 옵션을 통해서 해당 부분을 개선했다.
sns.pairplot(data=iris, hue="species")
plt.show()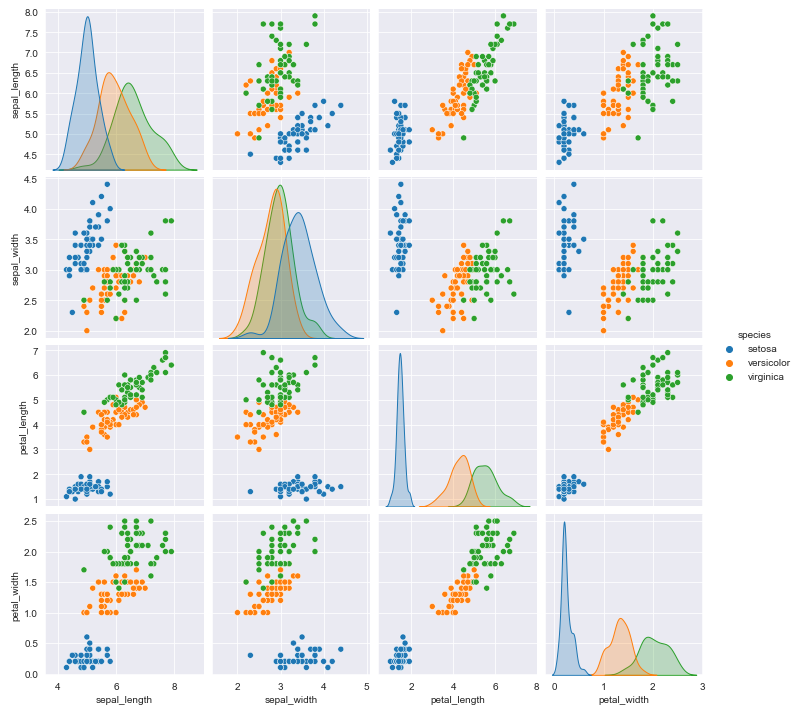
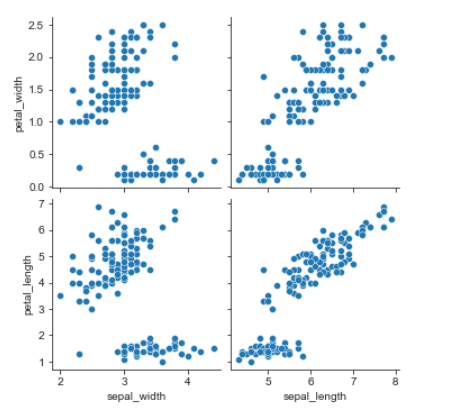
- 데이터를 보다가, sepal과 petal의 width, length만 따로 보고 싶다면, x_vars, y_vars를 이용한다.
sns.pairplot(
data=iris,
x_vars=["sepal_width", "sepal_length"],
y_vars=["petal_width", "petal_length"],
)
- 참고로 그냥 값만 지정해주려면 var로 지정하면 된다.
정리한 데이터 시각화하기
- 처음에 정리한 데이터를 다시 불러와보자.
crime_anal_norm.head()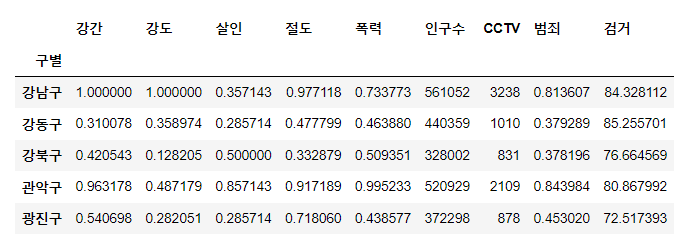
- 구에 대한 다양한 기준의 값들이 있기 때문에, 일단 "강도, 살인, 폭력"에 대한 pairplot을 그려보자.
sns.pairplot(
data=crime_anal_norm,
var=["강도","살인","폭력"],
kind="reg",
height=3
)
plt.show()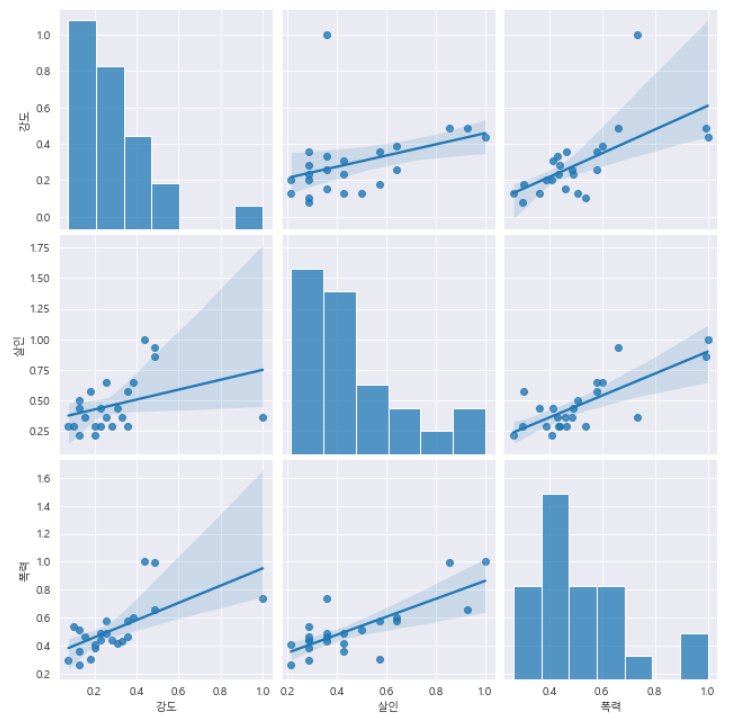
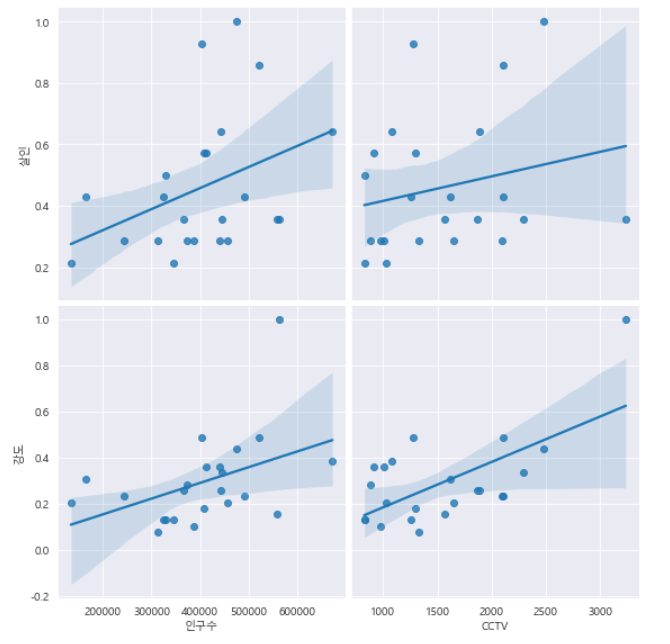
- 인구수, CCTV와 살인, 강도 사이의 상관관계를 보여주는 pairplot을 그려보자.
sns.pairplot(
data=crime_anal_norm,
x_var=["인구수", "CCTV"],
y_var=["살인", "강도"],
kind="reg",
height=4
)
- 검거 컬럼을 추가해서, 검거를 기준으로 내림차순 정렬한 데이터를 crime_anal_norm_sort라고 했다.
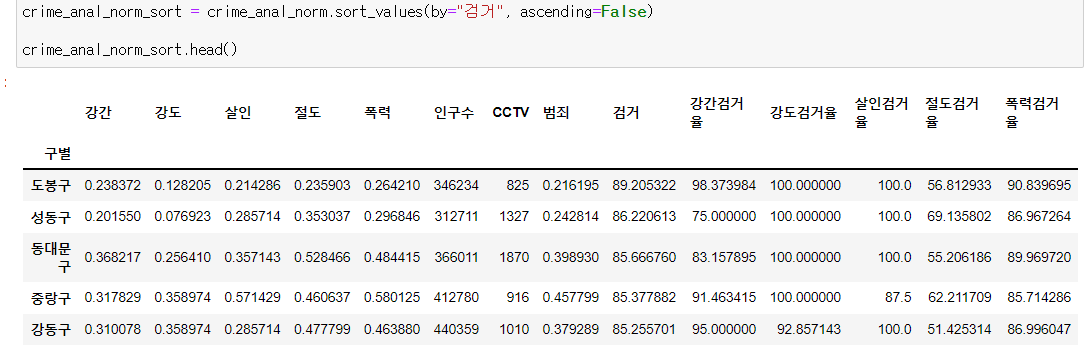
- 그리고 이 데이터를 활용해서, 각 행정구와 범죄검거율 사이의 heatmap을 그려봤다.
plt.figure(figsize=(10,10))
sns.heatmap(
data=crime_anal_norm_sort[['강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율']],
annot=True,
fmt="f",
cmap="RdPu",
linewidths="5"
)
plt.title("범죄 검거 비율(정규화된 검거의 합으로 정렬")
plt.show()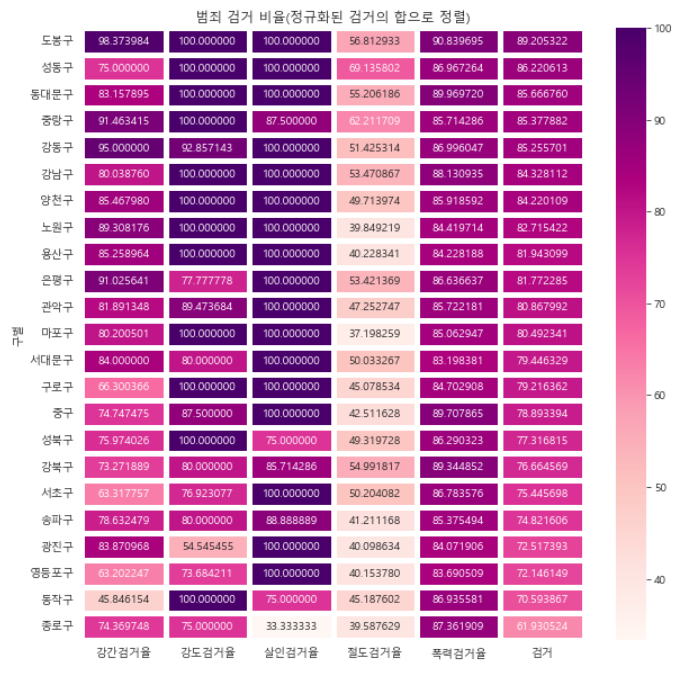
- 범죄 컬럼을 기준으로 내림차순 정렬하고, 각 구별 "강간, 강도, 살인, 절도, 폭력, 범죄"의 Heatmap을 그려봤다.
plt.figure(figsize=(15,15))
crime_anal_norm_sort = crime_anal_norm.sort_value(by="범죄", ascending=False)
sns.heatmap(
data=crime_anal_norm_sort[['강간', '강도', '살인', '절도', '폭력', '범죄']],
annot=True,
fmt="f",
cmap="RdPu",
linewidths=5
)
plt.title("범죄 검거 비율")
plt.show()
시각화 여섯째 날 후기
그래프 종류에 따라 문법에 차이가 좀 있는 듯하다.
정리를 좀 하면서 외워야겠다..
생각보다 빡센데?
더 다양한 그래프 종류가 있겠지만, 지금 정리한 것들을 가장 많이 활용할 것 같다.
- 네카라쿠배 데이터사이언스 오프라인 1기 수강 中
제로베이스 - 밑바닥부터 끝까지 듣는 온라인 강의
무조건 간다! 개발자 스쿨 '네카라쿠배', 끝까지 공부하는 '온라인 완주반', 전문가가 베스트셀러를 해석해 주는 '한달한권' 등 교육 서비스로 삶의 전환점을 제공하는 제로베이스입니다.
zero-base.co.kr
'Data Science' 카테고리의 다른 글
| [pandas.pivot_table] 피봇테이블, 개꿀. (0) | 2021.10.13 |
|---|---|
| [matplotlib] colormap 형태의 산점도와 선형 회귀식, 그리고 오차 표현 (0) | 2021.10.13 |
| [matplotlib] 데이터 다듬어서 간단한 시각화 다뤄보기 (0) | 2021.10.13 |
| [pandas] DataFrame(데이터프레임) 쪽지시험;Quiz 후기 (0) | 2021.10.07 |
| [Pandas] DataFrame(데이터프레임) 알아보기 (0) | 2021.10.06 |




댓글