# 홀로서기 기획 연재물은 최근 개인 프로젝트를 진행하면서 겪은 어려움들을 기록한 지극히 개인적인 콘텐츠입니다.
VS Code + SQL = 신세계 !!
필자는 데이터 비전공자다. 2021년 초에 스마트시티 관련 사업에 참여하면서, 데이터 비즈니스에 대한 전망을 봤다. 그리고 하반기부터 데이터를 공부하겠다고 마음 먹고, 전업을 잠시 접고 ML과 데이터 관련 학습에 매진하는 중이다. 파이썬의 '파', 아니지 'ㅍ'도 몰랐던 시절이 있었는데, 지금은 Jupyter Notebook의 테마를 바꿔보자며, 취향껏 공부를 하는 수준에 이르렀다.
그리고 최근에는 SQL 프로젝트를 진행하면서, VS Code를 쓰기 시작했다. 터미널 따로, Jupyter 웹 따로 두니까 너무 불편했었다. 하지만 지금은 VS Code에서 바로 SQL도 만지고, Python도 만지고, Terminal도 둘러보게 되었다. 편리하다.

오른쪽 하단을 보면 'bash', 'mysql' 등 터미널이 무엇을 하고 있는지를 보여준다. 기본 command를 켜둘 수도 있고, GitBash나 Anaconda 터미널을 켜둘 수도 있다. 선택 가능하다. VS Code로 Jupyter 환경을 불러올 수도 있기 때문에, 그냥 Python을 활용할 때도 유용할 것이다.
누가 그랬었는데, '응당 개발자라면..' 터미널로 일할 줄 알아야한다고.
VIEW? 그게 뭔데.
지난 1화에서 언급했던 대로, sqlalchemy의 Bulk insert를 통해서 약 800만 개 이상의 데이터셋을 적재했었다. 여기서 문제는 EDA를 진행하면서 발생했는데, 쿼리를 작성해서 SELECT를 할 때마다 18-20초의 시간이 소요되는 것이었다.
말 그대로 탐색적 데이터 분석(Exploratory Data Analysis)인데, 보고싶은 데이터가 많은데, 돌려야 할 쿼리가 많은데, 한번 찍을 때마다 20초씩 기다리면서 분석하기는 힘들다는 생각이 들었다. (해보지도 않았으면서 이런 생각을 가지는 내 문제일 수도 있다..)
그래서 알게 된 VIEW. 뷰 테이블이라고 흔히 부른다. 자주 쓰는 쿼리의 결과물을 가상 테이블(View)로 만들어서 활용하는 것이다.
['뷰(View) 테이블']
- 하나의 가상 테이블을 만들어 두는 기능
- 실제 데이터가 하드웨어에 저장되는 것은 아니지만, 뷰를 통해 데이터를 별도로 관리할 수 있다.
- 복잡한 Query로부터 결과를 얻는 과정를 View로 저장해두고 간단한 Query로 얻을 수 있도록 바꿔준다.
['뷰(View) 테이블'의 목적]
- 사용상의 편의 - 계속해서 쿼리를 부르면 시간도 오래 걸리고, 무엇보다도 '귀찮다'
- 수행 속도의 향상 - 가상 테이블을 따로 저장해두고 바로 불러오기 때문에, 기존 쿼리 실행보다 빠르다.
- SQL의 성능 향상 - SQL 자체의 성능을 향상시킬 때도 활용한다.
- 임시적인 작업을 위해 활용 - EDA 처럼 데이터를 전체적으로 확인하거나 잠시 편의상 해둘 작업을 위해 활용한다.
뷰 테이블 만들어서 써 보기
일단 뷰 테이블을 만들 기존의 테이블을 확인해야 한다. 뷰 테이블은 결국에 기존에 있는 테이블에서 조건에 맞는 각 컬럼을 참조해서 가상의 테이블을 만드는 프로세스이기 때문이다. 컬럼도 확인하고, 조건도 미리 확인해두면 좋다.
(그래서, 보통 쿼리가 너무 길어지는데, 이 긴 쿼리를 계속 치기가 힘든 경우에 뷰 테이블을 만드는 경우가 많다. 이런 경우라면, 있던 코드 그대로 써서 View로만 바꾸면 되겠다.)

필자는 대여 시간(time_start)에서 해당 월, 일, 요일, 시간 정보를 각 함수를 활용해서 뽑을 생각이다. 그리고, 실질적으로 EDA에 필요한 컬럼을 선택해서 뷰 테이블로 만들고자 했다.
- EXTRACT 함수를 사용해도 되지만, 연/월/일/시간 함수가 별도로 있기 때문에, 해당 함수를 활용했다.
- 연 추출 : YEAR(column_name)
- 월 추출 : MONTH(column_name)
- 일 추출 : DAY(column_name)
- 요일 추출 : DAYOFWEEK(column_name)
- 시간 추출 : HOUR(column_name)
- 분 추출 : MINUTE(column_name)
- 초 추출 : SECOND(column_name)
정류소별 수요량을 예측하고자 하므로, 빌리는 시간, 정류소 정보, 대여된 자전거의 이용 정보 등을 컬럼으로 정했다. 그리고, CREATE VIEW를 진행했다. (강남역 부근의 정류장 5개를 먼저 View로 뽑아봤다.)
CREATE VIEW Gangnam_stops AS
SELECT time_start
, stop_index1
, cycle
, distance
, MONTH(time_start)
, DAY(time_start)
, DAYOFWEEK(time_start)
, HOUR(time_start)
FROM User
WHERE (time_start >= '2021-03-01')
AND (stop_index1 in (2231, 2407, 3628, 2505, 2409))
ORDER BY time_start DESC;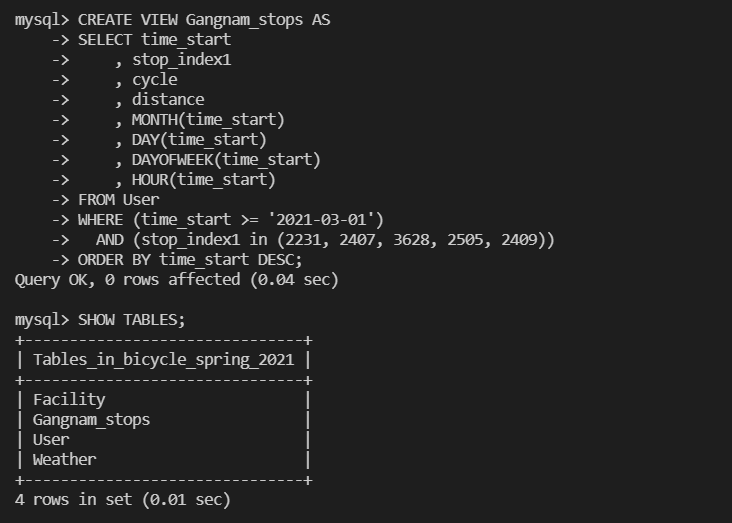
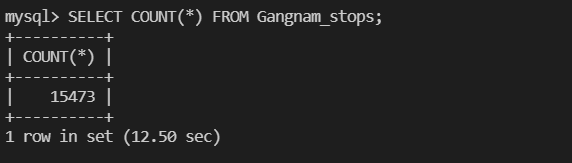
눈에 띄는 차이가 보이는 것을 알 수 있다. 뷰 테이블이라고 3초, 5초 만에 조회되지는 않는다. (그걸 기대했다면, 빅데이터를 너무 무시한 게 아니냐고..) 분명한 것은 기존에 그냥 테이블을 사용하는 것보다, 1) SQL 쿼리도 간편해졌고, 2) 속도도 몇 초는 절약할 수 있다. 이 정도면 그래도 '시간이 꽤나 절약되었구나'하는 마음으로 EDA를 진행할 수 있을 것 같다.
-- CREATE VIEW
CREATE VIEW Gangnam_stops AS
SELECT time_start
, stop_index1
, cycle
, distance
, MONTH(time_start)
, DAY(time_start)
, DAYOFWEEK(time_start)
, HOUR(time_start)
FROM User
WHERE (time_start >= '2021-03-01')
AND (stop_index1 in (2231, 2407, 3628, 2505, 2409))
ORDER BY time_start DESC;
-- DROP VIEW
DROP VIEW Gangnam_stops- Create와 Drop 문법을 간단히 정리했다.

Python 만큼 시각화를 동시에 할 수는 없지만,
SQL은 직관적인 언어라서 손쉽게 EDA를 할 수 있다.
빠르게 수치나 Describe를 훑어보기에 매우 유용한 것 같다.
다음 화에서는 모델링을 진행해보도록 하겠다. 홀로서기 #2 끝.
'Data Science > Project' 카테고리의 다른 글
| [홀로서기 #06] 회귀 Regression 결정계수(R^2), 알파(alpha) (0) | 2022.01.11 |
|---|---|
| [홀로서기 #05] 회귀 모델링 하기 전에 꼭 확인하기 (2) - 타겟 분포 (Log Transformation) (0) | 2022.01.03 |
| [홀로서기 #04] 회귀 모델링 하기 전에 꼭 확인하기 (1) - 범주형 특성 변수(Categorical Features) (0) | 2021.12.28 |
| [홀로서기 #03] SQL EDA, Python으로 쉽게 시각화하기 (0) | 2021.12.21 |
| [홀로서기 #01] Python에서 대용량 데이터 SQL에 적재(Insert)하기 (0) | 2021.12.07 |




댓글