# 홀로서기 기획 연재물은 최근 개인 프로젝트를 진행하면서 겪은 어려움들을 기록한 지극히 개인적인 콘텐츠입니다.
비지도학습 기반 이상탐지 모델
비지도학습에 활용되는 ML 모델로는 크게 아래와 같이 정리된다. (물론 딥러닝이나 최신 모델도 많지만 내 구글링 기준으로..)
| 1. Isolation Forest (가장 흔하고 쉽고 인기 있는 모델, 트리 기반) 2. Local Outlier Factor Algorithm (근접 기반) 3. One Class SVM 4. Random Cut Forest(Isolation Forest 변형) |
IF는 흔히 AI콘테스트에서 이상탐지 모델링 문제가 나왔을 때, 베이스라인 코드로도 많이 활용되는 기초 모델이다. 한번도 활용해본 적이 없기 때문에, 현재 내 프로젝트 데이터를 기반으로 Python 모델링을 한번 빠르게 수행해보고자 한다. 기본 베이스라인 코드(IF)를 기준으로, 전처리를 거의 진행하지 않고 일단 성능이 어느 정도 나오는지 확인한다.
베이스라인 코드 (Isolation Forest)
데이콘에서 제공하는 IF Baseline 코드이다. 대충 데이터 분포와 모양만 살펴보고 모델 불러와서 학습시키는 코드라고 보면 된다. 결과적으로 추론 결과를 제출하면, macro F1 기준 0.6422420502 정도 나온다. 굉장히 예측을 못하고 있는 것이다. 그렇다고 하더라도, 베이스라인은 무시할 수 없다. 적어도 이 F1 이상은 나와야 데이터 분석을 잘 해내고 있다는 것이고, 적어도 베이스라인만 잘 따라가도 '이상탐지는 이렇게 하는 것이구나' 하는 가닥도 잡을 수 있으니까 말이다. 참고로 필자는 코랩 프로(Colab Pro) 환경에서 진행했다.
1) Import Library
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.gridspec as gridspec
import warnings
warnings.filterwarnings(action='ignore')
from sklearn.ensemble import IsolationForest
from sklearn.metrics import f1_score
from sklearn.metrics import classification_report
2) Load Data : Train, Valid, Test 데이터가 모두 따로 제공됨
- 비지도학습답게, Valid에만 Class가 달려있다. ID는 의미가 없으므로, 모델에 들어갈 때 drop하면 될 것 같다.
train = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/DACON-AD-Card-Fraud/train.csv')
train.head()
valid = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/DACON-AD-Card-Fraud/val.csv')
valid.head()
3) Explore Dataset (Simple)
- Valid 쪽을 보면, Normal과 Fraud 분포의 색을 다르게 표시했는데, 구분 안 가는 컬럼이 몇몇 보이는 것을 알 수 있다.
- 이런 부분은 베이스라인을 개선하는 부분에서 고려해서 전처리 진행하면 좋을 것 같다.
train.drop(columns=['ID']).hist(bins = 50, figsize = (20,20))
plt.show()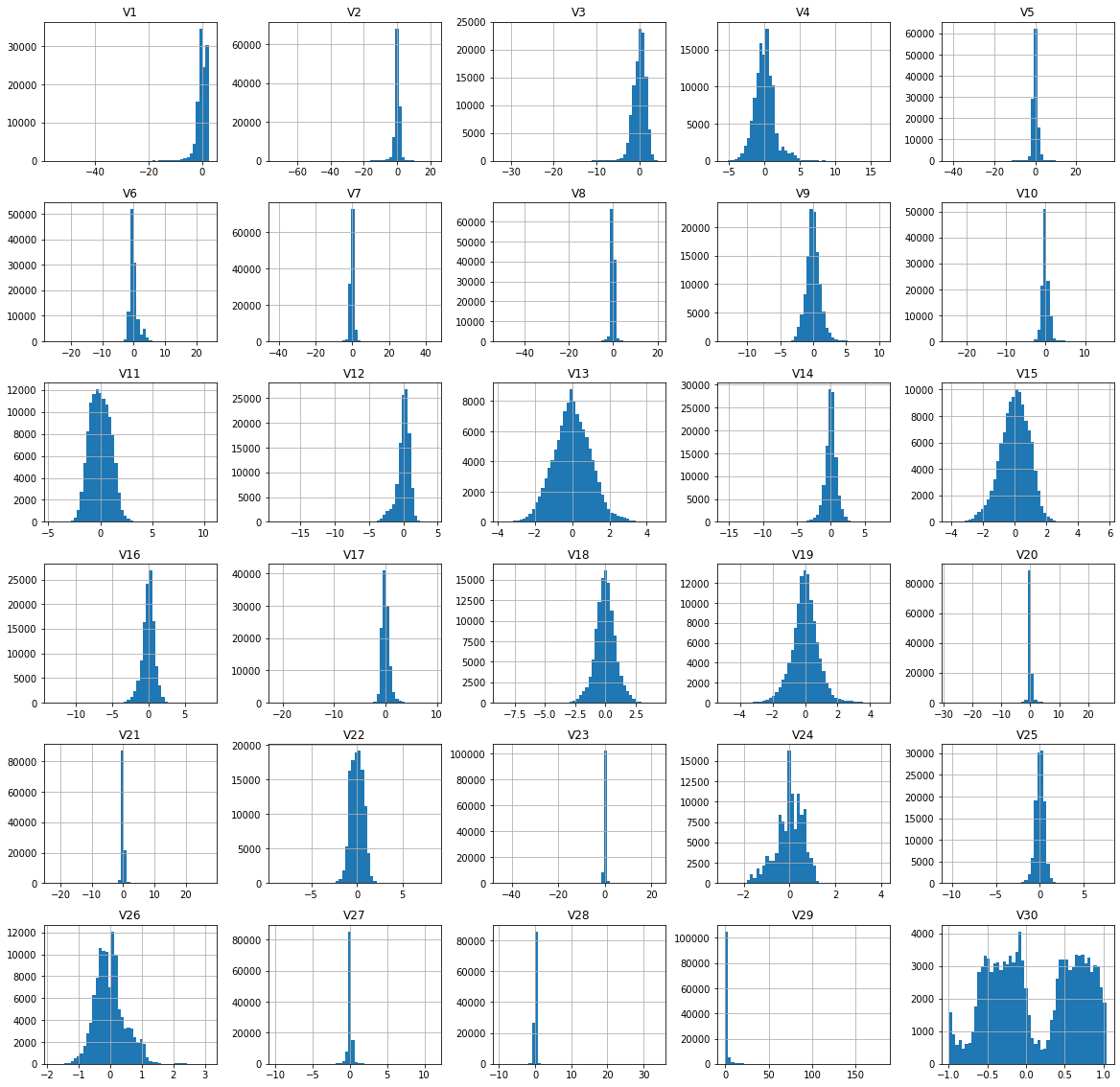
columns = valid.drop(columns=['ID', 'Class']).columns
grid = gridspec.GridSpec(6, 5)
plt.figure(figsize=(30, 25))
# 1 = Fraud
for n, col in enumerate(valid[columns]):
ax = plt.subplot(grid[n])
sns.distplot(valid[valid.Class==0][col], bins=50, color='g')
sns.distplot(valid[valid.Class==1][col], bins=50, color='r')
ax.set_ylabel('Density')
ax.set_title(str(col))
ax.set_xlabel('')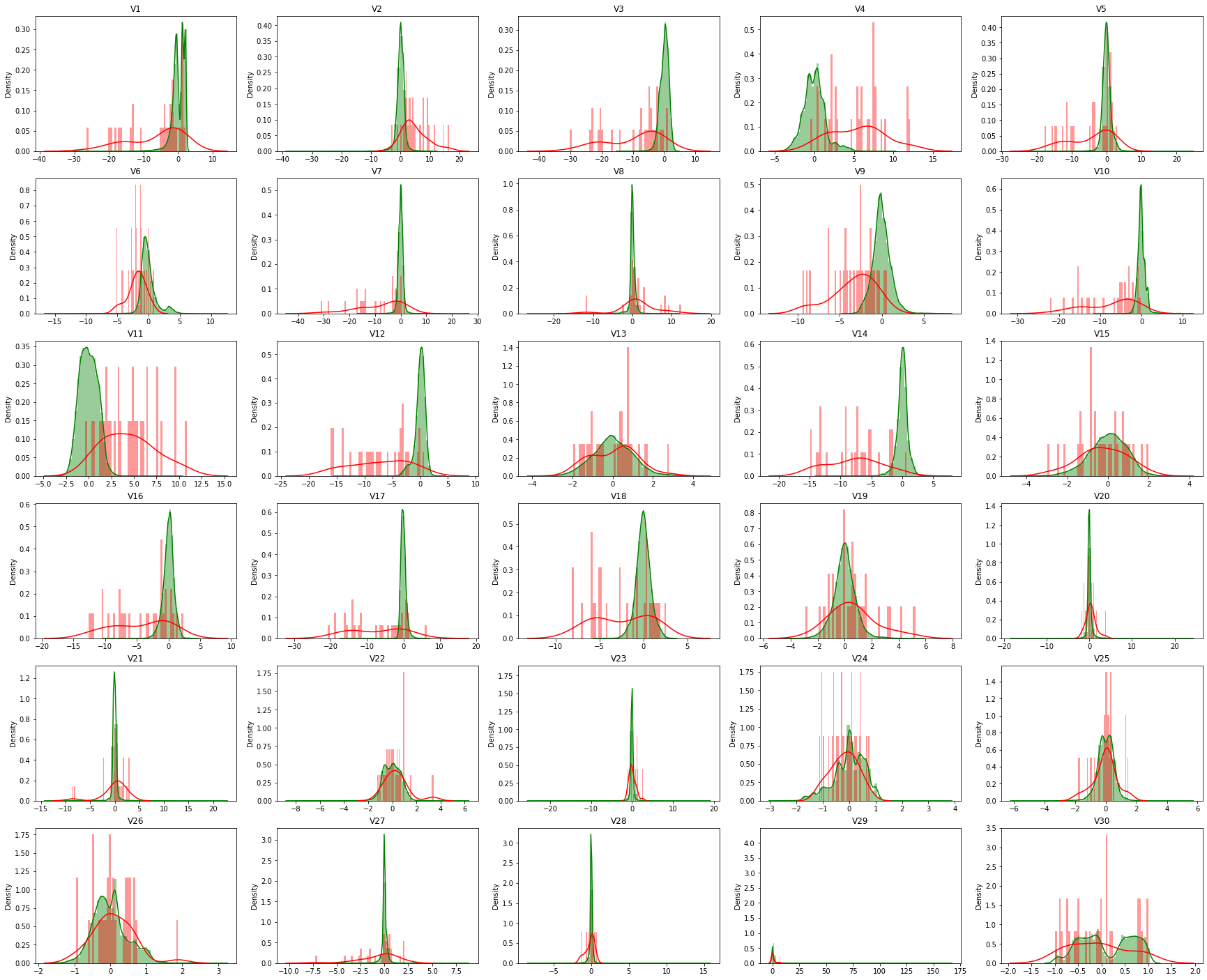
4) Set Contamination Ratio
- Train 데이터에서 사기 거래 데이터가 얼마나 포함되어 있는지 알 수 없기 때문에,
- IF 모델링 시에는 Contamination Ratio를 넣어주어야 한다. (대충 이상치 이정도 된다고 말해주는?)
- 그래서 Valid 데이터 기준으로 사기 거래 비율을 설정했다. (유사한 비율일 것이라고 가정)
# Validation set 사기 거래 비율
# (*) Validation set의 사기 거래 비율이 다른 데이터집합에서도 비슷하게 발생할 것이라고 가정
val_normal, val_fraud = valid['Class'].value_counts()
val_contamination = val_fraud / val_normal
print(f'Validation contamination : [{val_contamination}]')
5) Define Model and Train
# Model Define & Fit
# Train dataset은 Label이 존재하지 않음
X_train = train.drop(columns=['ID']) # Input Data
# 가설 설정 : Train dataset도 Validation dataset과 동일한 비율로 사기거래가 발생 했을 것이다. -> model parameter : contamination=val_contamination(=0.001055) 적용
model = IsolationForest(n_estimators=125, max_samples=len(X_train), contamination=val_contamination, random_state=42, verbose=0)
model.fit(X_train)
6) Evaluation
- Valid 데이터를 모델 평가에 활용함
- IF 모델 출력이 1. -1로 되기 때문에, 평가를 위해서는 해당 결과를 1, 0으로 바꾸어주어야 함
- get_pred_label이라는 함수를 정의
- Valid 데이터 기준 F1 Score는 약 0.7031 정도 나옴
# Evaluation : Validation set
def get_pred_label(model_pred):
# IsolationForest 모델 출력 (1:정상, -1:불량(사기)) 이므로 (0:정상, 1:불량(사기))로 Label 변환
model_pred = np.where(model_pred == 1, 0, model_pred)
model_pred = np.where(model_pred == -1, 1, model_pred)
return model_pred
X_valid = valid.drop(columns=['ID', 'Class']) # Input Data
y_valid = valid['Class'] # Label
y_pred_valid = model.predict(X_valid) # model prediction
y_pred_valid = get_pred_label(y_pred_valid)
val_score = f1_score(y_valid, y_pred_valid, average='macro')
print(f'Validation F1 Score : [{val_score}]')
print(classification_report(y_valid, y_pred_valid))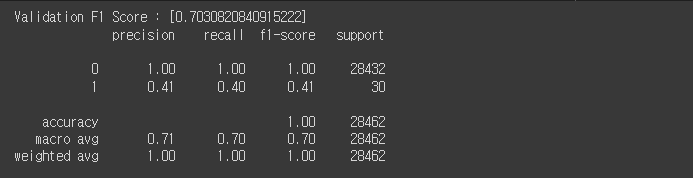
7) Predict Unseen Data (Inference)
- test 데이터를 불러와서 추론 진행
- 결과값을 제출 양식(sample_submission)에 추가하고 저장 → 데이콘 제출 페이지에 해당 csv 파일 제출하면 됨
# Inference : Test set
test = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/DACON-AD-Card-Fraud/test.csv')
test.head()
X_test = test.drop(columns=['ID'])
y_pred_test = model.predict(X_test) # model prediction
y_pred_test = get_pred_label(y_pred_test)
submission = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/DACON-AD-Card-Fraud/sample_submission.csv')
submission['Class'] = y_pred_test
submission.to_csv('/content/drive/MyDrive/Colab Notebooks/DACON-AD-Card-Fraud/submit0.csv', index=False)
이렇게 하면 베이스라인 코드를 한번 둘러보게 된 거다. 제출 결과 Public Score는 macro F1 기준 약 0.6422 정도 나왔다. 베이스라인일 뿐이니까! 여기서 더 개선하면 될 듯하다. (다른 모델들도 여기서 갈아끼우거나, pipeline 모듈로 여러 개 모델의 성능을 비교하는 것도 좋을 듯)
예측 결과 시각화해보기
차원축소 알고리즘을 활용해서, 2차원으로 특성을 압축하고, 이를 2차원에 그려보도록 한다. 차원축소에 활용하는 알고리즘은 크게 1) PCA, 2) t-SNE를 활용해봤다. 둘 중에 무엇을 써도 상관은 없으나, 나는 비교해보고 싶어서 둘다 시도해봤다.
1) PCA
- 시각화는 plotly.express 라이브러리 내에 있는 scatter로 진행했음
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca_result = pca.fit_transform(X_valid.values)
valid['pca_one'] = pca_result[:, 0]
valid['pca_two'] = pca_result[:, 1]
import plotly.express as px
fig = px.scatter(data_frame=valid, x='pca_one', y='pca_two', color='Class')
fig.update_traces(marker_size=15)
fig.show()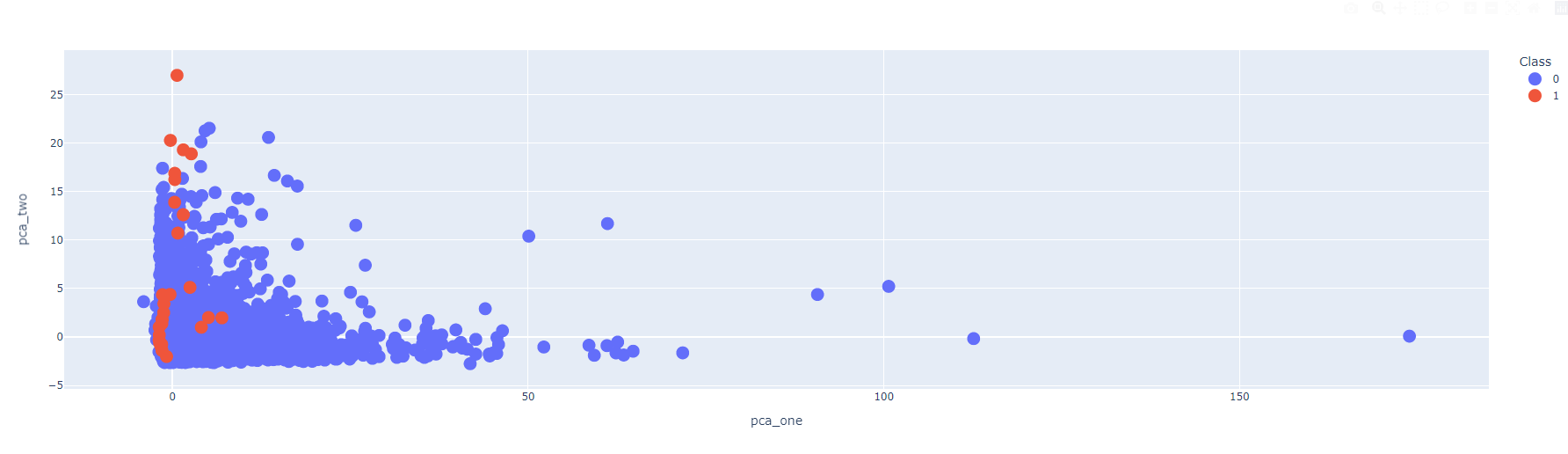
2) t-SNE
- t-SNE는 N개의 데이터가 있을 때 N^2만큼 시간이 걸리기 때문에 실제 데이터를 분석하는 데 있어서는 제한적일 수 있음
- 그래서 0.3 비율의 샘플을 뽑아서 진행함
from sklearn.manifold import TSNE
n_sne = len(sample)
tsne = TSNE(n_components=2, verbose=1, perplexity=40, n_iter=300)
tsne_result = tsne.fit_transform(sample.iloc[:, 1:31])
sample['tsne_one'] = tsne_result[:, 0]
sample['tsne_two'] = tsne_result[:, 1]
import plotly.express as px
fig = px.scatter(data_frame=sample, x='tsne_one', y='tsne_two', color='Class')
fig.update_traces(marker_size=15)
fig.show()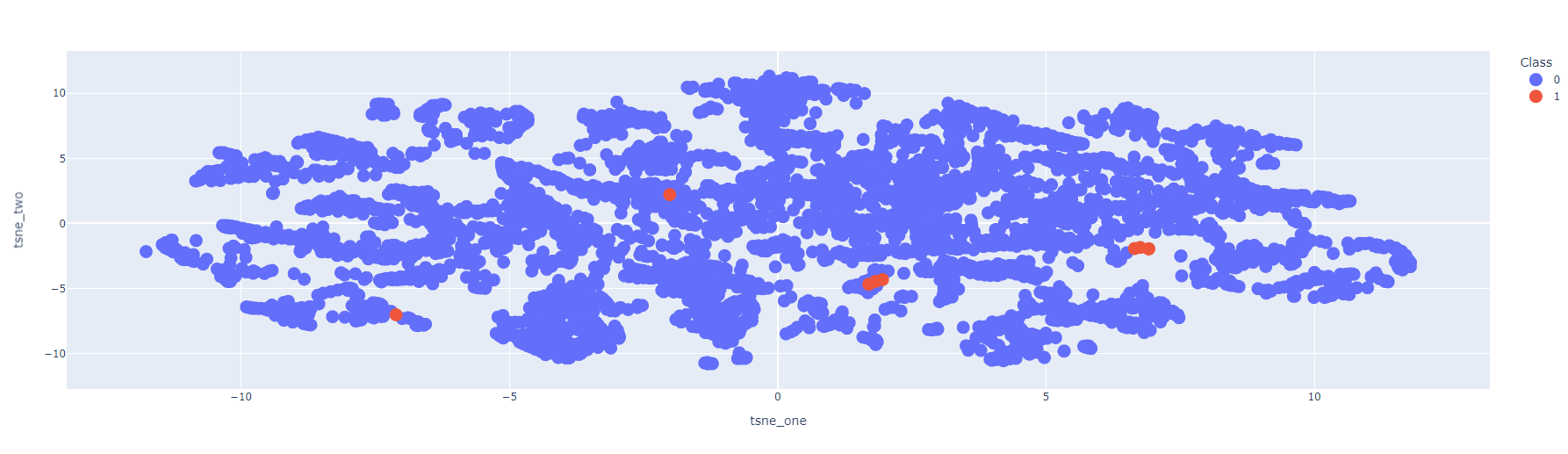
이상 탐지와 관련한 가장 기초적인 모델로 꼽히는 IF 알고리즘을 베이스라인으로 진행했다.
그리고 그 결과를 시각화해서 살펴보았는데, 아직 갈 길이 먼 듯하다.
머신러닝으로 이상탐지가 매우 어렵다는 것은 알고 있었는데,
정말 갈 길이 먼 것 같다. 요호~
홀로서기 #9 끝.
'Data Science > Project' 카테고리의 다른 글
| [홀로서기 #10] 하이퍼 파라미터 튜닝 & Feature Engineering 경험하기 (Feat. 다중공선성, VIF, Z-test) (0) | 2022.07.15 |
|---|---|
| [홀로서기 #08] 이상 탐지(Anomaly Detection) 베이직. (0) | 2022.07.13 |
| [홀로서기 #07] 80 Features, 8M Records... Pandas 말고 Dask! (1) | 2022.01.19 |
| [홀로서기 #06] 회귀 Regression 결정계수(R^2), 알파(alpha) (0) | 2022.01.11 |
| [홀로서기 #05] 회귀 모델링 하기 전에 꼭 확인하기 (2) - 타겟 분포 (Log Transformation) (0) | 2022.01.03 |




댓글