# 홀로서기 기획 연재물은 최근 개인 프로젝트를 진행하면서 겪은 어려움들을 기록한 지극히 개인적인 콘텐츠입니다.
Isolation Forest의 하이퍼 파라미터...?
하이퍼 파라미터(Hyper parameter)는 초매개변수라고도 하며, 모델링할 때 사용자가 직접 세팅해주는 값을 뜻한다. 베이스라인에서 성능을 대폭 올릴 수는 없지만, 어느 정도 상위로 끌어올리기 위해서는 하이퍼 파라미터를 튜닝하는 작업이 필요하다. 보통은 GridSearchCV(그리드서치 교차검증)를 통해서, 교차검증과 최적의 하이퍼파라미터 튜닝을 한번에 수행하는 것이 일반적인 듯하다.
하지만, 내 프로젝트에서 사용하기 어렵다는 것을 알게 되었다. 그래서 그냥 파라미터를 일일히 리스트에 넣어서 for문으로 돌려버렸다. GridSearchCV는 scikit-learn 라이브러리에서 지원하고 있는데, 공식 docs를 보면, validation을 위한 데이터셋을 별도로 지정하기가 힘들도록 되어 있다. (딥러닝에서는 Validation_set=(X_val, y_val) 이런 형태로 넣었던 기억이 있어서 이것도 별도로 지정할 수 있겠지.. 하는 나의 바람이 있었다. 그래서 시간을 더욱 소비했다.)
*sklearn.model_selection.GridSearchCV 공식 docs 참고
sklearn.model_selection.GridSearchCV
Examples using sklearn.model_selection.GridSearchCV: Release Highlights for scikit-learn 0.24 Release Highlights for scikit-learn 0.24, Feature agglomeration vs. univariate selection Feature agglom...
scikit-learn.org
그래서 내가 조정한 하이퍼파라미터는 n_estimators와 contamination이다.
| * n_estimators - (docs) The number of base estimators in the ensemble. - 앙상블에 활용할 분류기의 수 - 많을 수록 좋은 성능을 기대할 수 있지만, 반드시 좋아지는 것은 아니고, 너무 많아지면 학습 수행 시간이 매우 오래 소요) * contamination - (docs) The amount of contamination of the data set - 이상 데이터의 숫자가 얼마나 되는가? 비율로 넣어줌 |
다른 파라미터도 굉장히 많지만, 뭔가 직관적으로 튜닝하기 좋은 파라미터라고 생각했고, 이후에 말하겠지만, 튜닝 이후에도 큰 성능의 차이가 느껴지지 않아서 다른 방법이 더 낫겠다고 판단했다.
하이퍼 파라미터 튜닝 수행
기존에 n_estimators=125, contamination=0.0010551491277433877로 진행했었다. 그래서 n_estimators는 100부터 100단위로 700까지, contamination은 [0.001, 0.002, 0.003, 0.005, 0.01]로 진행했다. 앞서 말했던 것처럼 GridSearch를 적용하기가 어려운 상황으로 판단되어 for문으로 반복문 적용하고, verdose를 직접 찍을 수 있도록 f-string print도 구현했다.
# parameter setting
n_estimators = list(range(100, 800, 100))
contamination = [0.001, 0.002, 0.003, 0.005, 0.01]
result = pd.DataFrame(columns=['n_estimators', 'contamination', 'f1'])
# fitting and check
for n_est in n_estimators:
for cont in contamination:
model = IsolationForest(n_estimators=n_est, max_samples=len(X_train), contamination=cont, random_state=42, verbose=0)
model.fit(X_train)
y_pred_valid = get_pred_label(model.predict(X_valid)) # model prediction and label conversion
f1 = f1_score(y_valid, y_pred_valid, average='macro')
result.loc[len(result)] = [n_est, cont, f1]
print(f'n_estimator : {n_est}, contamination : {cont} ====> f1 : {f1}')
해당 파라미터를 바탕으로, test dataset을 추론하여 제출했더니, 기존 베이스라인 코드 성능인 약 0.6422보다 소폭 상승한 약 0.7031의 f1 스코어를 얻을 수 있었다. (뿌듯)
Feature Check
1. VIF
*VIF(분산팽창요인, Variance Inflation Factor) : 변수간의 다중공선성을 진단하는 수치이며, 범위는 1부터 무한대이다.
- VIF 값이 10 이상이면 다중공선성이 있다고 판단한다.
혹시라도 변수들 중에서 다중공선성이 있어서 모델이 분류 자체를 혼동할 수 있을까 싶어, VIF를 체크해봤다. 물론 이 방법은 회귀 예측모델에서 쓰는 방법이라고 들었지만, 각 Feature들 사이의 상관관계가 있으면, 분류 자체에도 영향을 줄 수 있을 것이라는 생각이 들어서 진행했다. 실제로 확인해본 결과, V29 변수의 VIF가 다른 변수에 비해 굉장히 크게 나타나는 것을 알 수 있었다. 그래서 V29 변수는 제거하기로 결정했다.
- VIF는 파이썬 라이브러리 상에서 statsmodels.stats.outliers_influence 모듈에서 지원하고 있다.
# VIF
vif = pd.DataFrame()
vif['VIF Factor'] = [variance_inflation_factor(train.values, i) for i in range(train.shape[1])]
vif['features'] = train.columns
vif = vif.sort_values('VIF Factor', ascending=False).reset_index(drop=True)
vif
2. StandardScaler
이후에는, 기본적인 전처리에 해당하는 Standard Scaler(정규화 스케일링 작업)를 진행했다. 애초에 처음부터 정규화 작업은 진행하면 좋았을텐데, 베이스라인에서도 제외되어 있어서 진행하지 않았던 것 같다.
- 스케일러는 sklearn.preprocessing 모듈 내에서 지원되고 있다.
# StandardScaler
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
X_train_ss = ss.fit_transform(X_train_removed)
X_valid_ss = ss.transform(X_valid_removed)
3. Z-test for Feature Selection
직감적으로, Feature를 고작 1개 제외(고작이라는 표현은 위험하지만 좀 더 노력하고 싶다는 의미에 논리를 더하고자 이 표현을 적었을 뿐이다. 1개를 제외해도 분명 모델 성능은 현저히 다를 수 있다.)하고, 정규화 작업만 수행했기 때문에, 좀더 전처리나 Feature Engineering이 필요하다고 생각했다. 그래서, 처음으로 돌아가 정상치 데이터와 이상치 데이터의 모양을 다시 살펴보았다.
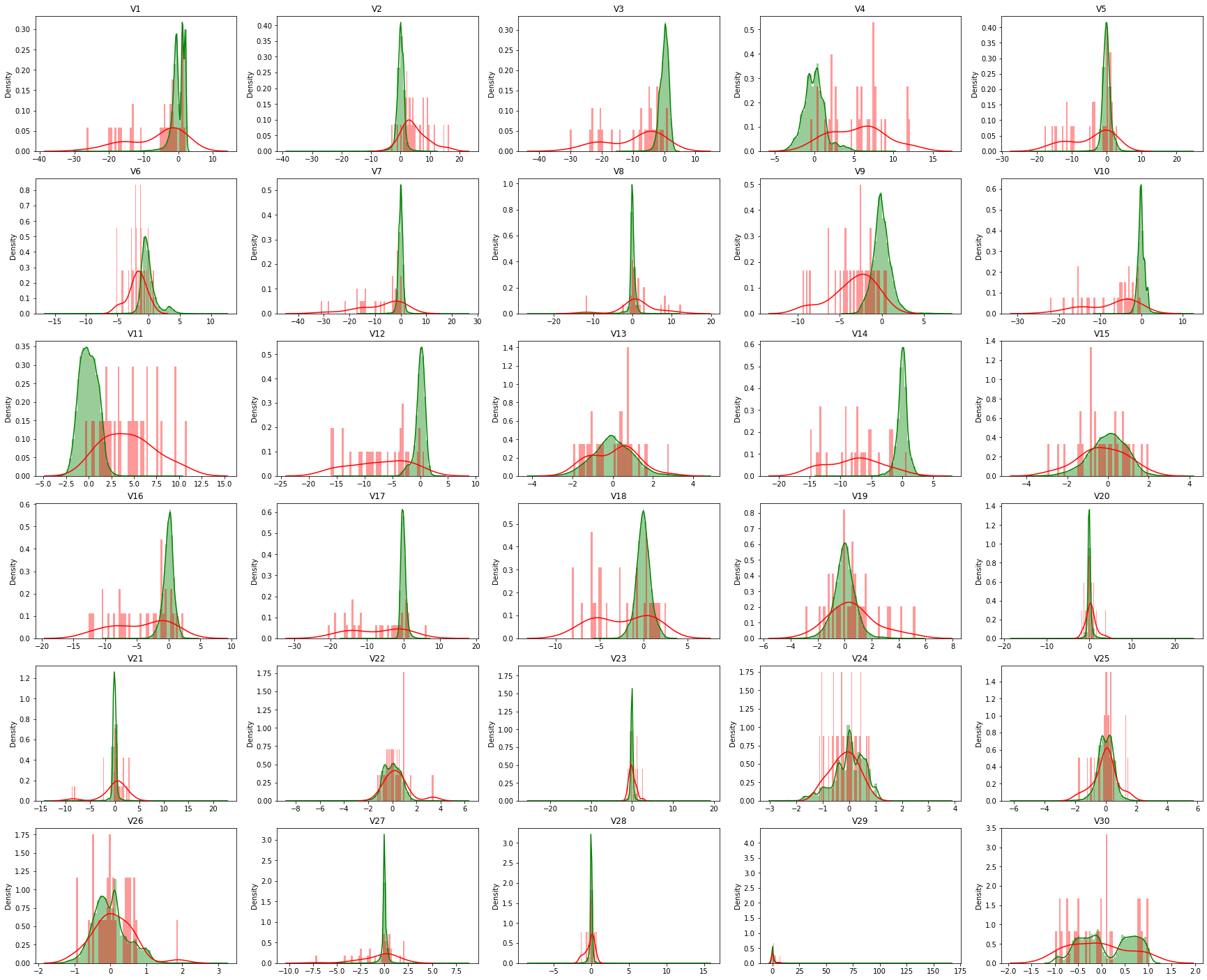
초록색으로 표시된 것이 정상(Normal) 데이터이고, 붉은색으로 표시된 것이 사기(Fraud, Anomaly) 데이터이다. 유심히 보다 보면, 초록색과 붉은색이 거의 차이가 없는 것처럼 느껴지는 특성(Column, Feature)이 있다는 생각이 들 수도 있다. 그래서 나는 정상 데이터와 이상 데이터 사이에 차이가 유의미하지 않은 특성이 무엇이 있는지 체크하고, 그 피쳐를 제외하는 작업을 수행했다. 이에 유용한 Test가 Z-Test라고 해서, 활용해봤다. (해당 내용은 캐글의 한 사용자의 노트북을 참고했다)
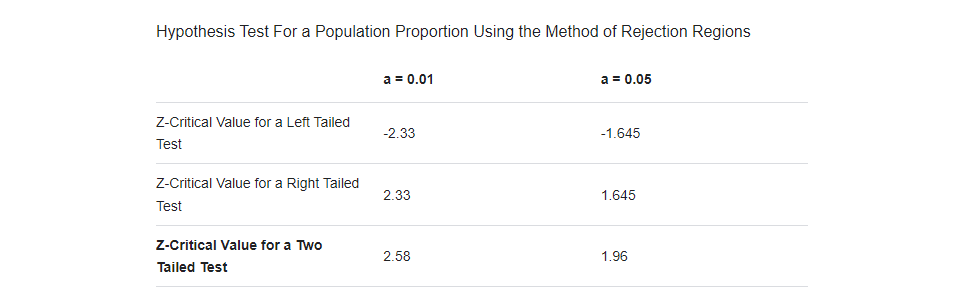
- code 상에 critical_value=2.58인 이유는 통계적으로 유의한지 아닌지와 관련한 확률(1-α)을 99%로 설정할 때, 그 value 값이 2.58이기 때문이다. (통계학 내용은 공부해도 늘 어렵고 힘든 것 같다.)
# feature selection with Z-test
def Ztest(feature):
mean = normal[feature].mean()
std = fraud[feature].std()
zScore = (fraud[feature].mean() - mean) / (std/np.sqrt(sample_size))
return zScore
valid_removed_ss = pd.concat([pd.DataFrame(X_valid_ss, columns=X_valid_removed.columns), y_valid], axis=1)
columns = X_train_ss_df.columns
normal = valid_removed_ss[valid_removed_ss.Class==0]
fraud = valid_removed_ss[valid_removed_ss.Class==1]
sample_size = len(fraud)
significant_features = []
critical_value=2.58
for i in columns:
z_value = Ztest(i)
if(abs(z_value) >= critical_value):
print(i," is statistically significant") # Reject Null hypothesis. i.e. H0
significant_features.append(i)

테스트를 통해서 선별된 컬럼으로 모델을 다시 학습시켰을 때, Validation 데이터 기준 약 0.7304의 f1 스코어가 나온다. (굳)

그리고, 해당 모델로 Test 데이터를 추론하고 제출했더니, 무려 0.7911390179의 Score를 받을 수 있었다. 이래서 데이터 사이언티스트들이 엔지니어링 업무를 정말 열심히 한다는 말이 그래서 그런거구나.. 생각했다.

점점 스코어가 올라가는 걸 눈으로 확인하니까, 욕심이 생기는 것 같다.
모델도 다양하게 써보고, 튜닝도 해보고, 데이터 엔지니어링도 시도해봐야겠다.
(딥러닝을 시도하는 것도 목표다..!)
홀로서기 #10 끝.
'Data Science > Project' 카테고리의 다른 글
| [홀로서기 #09] 이상 탐지 모델링 베이스라인(Isolation Forest) 빠르게 훑기 (0) | 2022.07.14 |
|---|---|
| [홀로서기 #08] 이상 탐지(Anomaly Detection) 베이직. (0) | 2022.07.13 |
| [홀로서기 #07] 80 Features, 8M Records... Pandas 말고 Dask! (1) | 2022.01.19 |
| [홀로서기 #06] 회귀 Regression 결정계수(R^2), 알파(alpha) (0) | 2022.01.11 |
| [홀로서기 #05] 회귀 모델링 하기 전에 꼭 확인하기 (2) - 타겟 분포 (Log Transformation) (0) | 2022.01.03 |




댓글